How to Fix Negative Brand Mentions in AI Search
Umar
AI engines spread wrong pricing, fabricated scandals, and outdated info about your brand. Learn how to find, prioritize, and fix negative AI mentions step by step

Your G2 rating is 4.8 stars. Your Trustpilot reviews are glowing. Your Google rankings look strong. But right now, someone is asking ChatGPT about your company and getting told you went through a data breach that never happened, or that your product costs twice what it actually does, or that a competitor is "the better alternative" based on a Reddit thread from 2023.
The worst part: you have no idea this is happening. Traditional monitoring tools track social mentions, news articles, and review sites. They can't see inside AI-generated responses, where an increasing share of your potential customers are forming their first impressions. According to recent data, 47% of marketers encounter AI-generated errors about their brands several times per week. And roughly 1 in 11 AI responses about brands contain fabricated or incorrect information.
This isn't a future risk. It's a current one. This guide walks through how to find negative or inaccurate AI mentions, decide which ones to fix first, and systematically correct them across platforms.
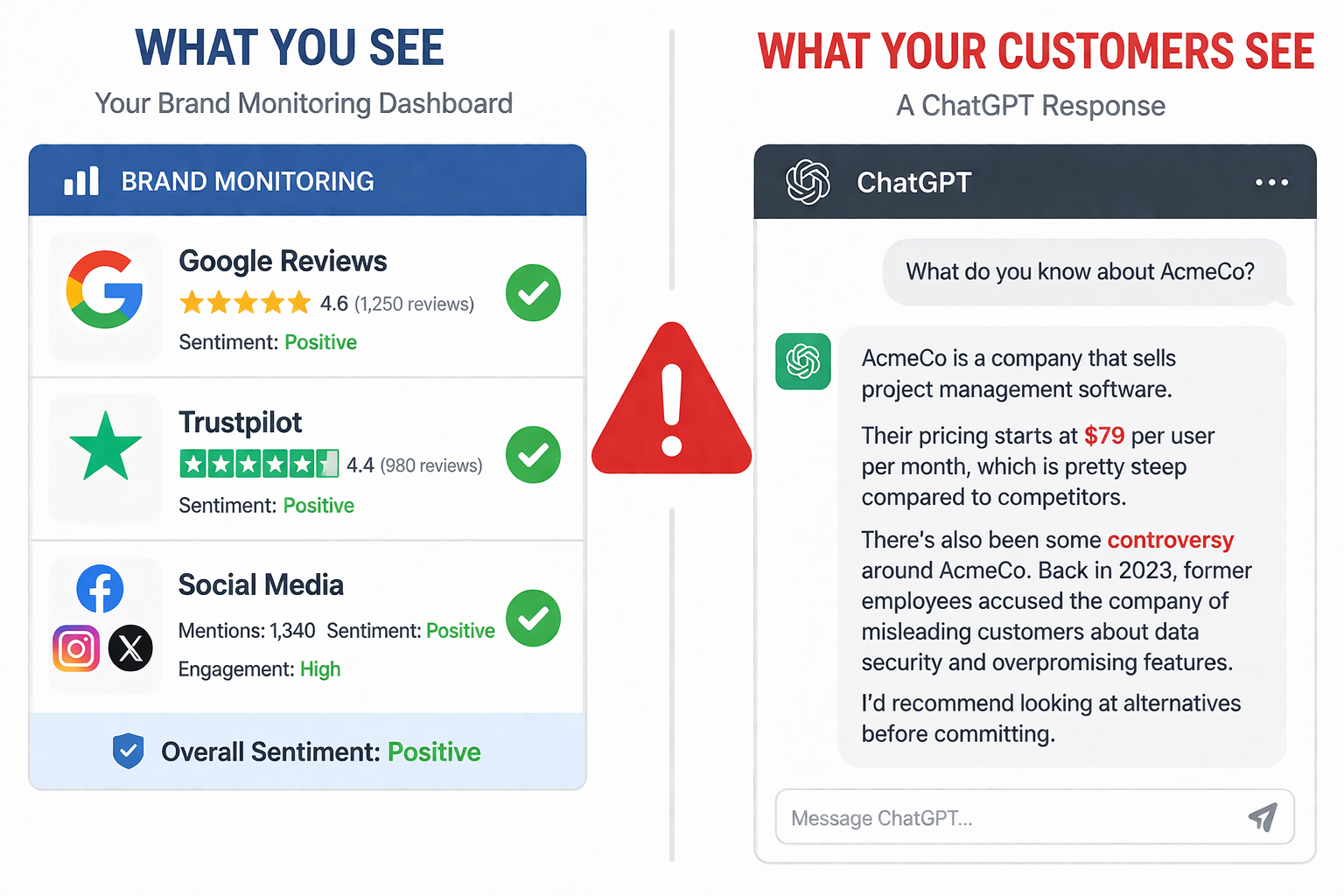
Why Traditional Reputation Management Doesn't Cover This
If your brand has been doing reputation management well, you probably monitor Google results, respond to reviews, and track social sentiment. That's necessary, but it misses the fastest-growing channel where brand perception is formed.
AI search works differently from traditional search in a way that matters for reputation. When someone Googles your brand, they see a list of links and decide what to click. When someone asks ChatGPT or Perplexity about your brand, they get a single synthesized answer that carries an authority bias. Users treat AI recommendations differently than random search results or social media opinions. The AI's answer becomes the first impression, and there's no list of alternative sources to balance it.
The problem gets worse when you consider where AI models pull information. LLMs cite Reddit and editorial content for over 60% of brand information, not corporate websites. A single active Reddit thread filled with complaints from three years ago can outweigh your entire website in shaping what ChatGPT says about you. Search Engine Land recently documented a case where Google AI Overview resurfaced an old Reddit forum of complaints about a company, creating a negative narrative from issues that had been resolved years earlier.
There are three distinct types of problems you might find:
AI hallucinations happen when an AI confidently generates false information. It states fabricated facts, wrong pricing, nonexistent controversies, or confused identities (mixing your brand with a competitor). These aren't drawn from any real source. The model invented them.
AI misinformation happens when an AI repeats outdated or biased information from its training data. The source material was once accurate but is now wrong. Your pricing changed, your product evolved, a negative issue was resolved, but the AI still references the old data.
Negative framing happens when the information is technically accurate but the AI consistently positions your brand unfavorably. It might always list you last, highlight limitations more than strengths, or frame competitors more positively using language like "better alternative."
Each type requires a different fix. Knowing which you're dealing with saves time.
Step 1: Audit What AI Actually Says About You
You can't fix what you don't know exists. Start with a systematic audit across platforms.
Run 30 to 50 queries across at least four platforms. Use ChatGPT, Perplexity, Gemini, and Claude at minimum. Ask the questions your customers would ask: "What is [your brand]?", "Is [your brand] reliable?", "[your brand] vs [competitor]", "best [your category] for [use case]", "what are the downsides of [your brand]?" Use your customers' language, not your marketing terminology.
Run each query multiple times. AI gives different answers each session. A single query tells you nothing. Running the same question 3 to 5 times reveals patterns and shows how consistently the problem appears.
Log everything in a spreadsheet. For each issue, record: the platform, the exact query, the problematic claim, whether it's a hallucination/misinformation/framing issue, and a severity rating (high/medium/low). This log becomes your remediation roadmap.
Trace the source. For misinformation and framing issues, ask the AI "what sources did you use for this information?" Search for the exact wrong phrasing in Google to find where the AI likely picked it up. If the same error appears on multiple platforms, it usually originates from a web source they both access. If it's only on one platform, it may be baked into that model's training data.
For ongoing monitoring at scale, tools like RepuAI automate this process across ChatGPT, Perplexity, Gemini, and Claude, tracking mentions, sentiment, and accuracy over time so you catch new issues as they appear rather than discovering them months later.
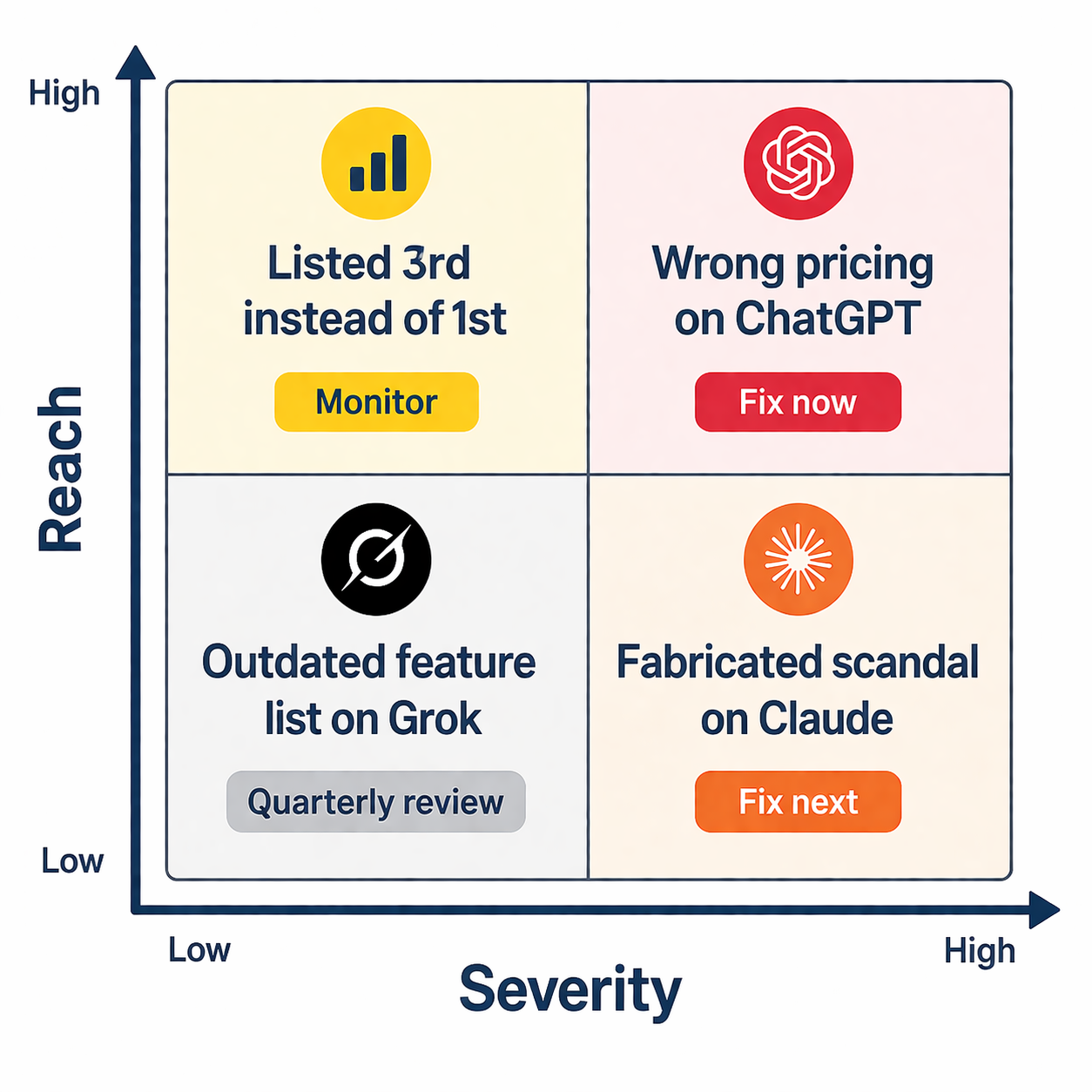
Step 2: Prioritize by Impact
Not every negative mention deserves the same urgency. Trying to fix everything at once spreads your effort too thin. Prioritize based on three factors:
Reach. Focus first on platforms with the most user exposure. ChatGPT handles roughly 77 to 80% of AI search traffic. If your biggest problem is on ChatGPT, fix that before worrying about a smaller platform. Google AI Overviews reach 2 billion monthly users, making them equally urgent when they surface inaccurate information.
Severity. Fabricated facts (wrong pricing, nonexistent scandals, confused identity) are more damaging than unfavorable framing. A customer who's told your product costs $500/month when it actually costs $50 will never reach your pricing page. A customer who sees you listed third instead of first might still click through.
Frequency. Track how consistently the error appears. If the wrong information shows up in 4 out of 5 queries on the same topic, it's embedded in the model's understanding and needs content-level intervention. If it appears in 1 out of 5, it may resolve naturally as the model accesses newer sources.
Create a simple priority matrix: high-reach + high-severity + high-frequency issues get fixed first. Low-reach + low-severity + low-frequency issues go into a quarterly review queue.
Step 3: Fix the Source Layer
The most effective fixes happen at the source level, not at the AI model level. AI engines synthesize from web content, so changing what's on the web changes what AI says about you over time.
Update your own content to be unambiguous. If AI gets your pricing wrong, make sure your pricing page states prices in clear, extractable text (not locked in images or JavaScript widgets). If AI confuses your product with a competitor, create explicit differentiation content. Include your correct information in the first 60 words of each relevant section, formatted so AI can extract it as a standalone fact. The content structuring techniques covered in our GEO guide apply directly here.
Strengthen your structured data. Schema markup gives AI systems machine-readable facts about your brand that are harder to misinterpret. Organization schema with accurate description, foundingDate, and knowsAbout properties helps AI engines build a correct entity profile. Product schema with current price and availability prevents pricing errors. Keep dateModified current on every page so AI knows your information is fresh.
Address the third-party sources causing problems. If you traced a specific error to an outdated comparison article or a Reddit thread, you have several options. Contact the publisher of outdated articles and ask for corrections or updates. Respond to inaccurate Reddit threads with factual, non-promotional corrections from a real account. Publish updated content on the same topic that provides accurate information. Earn new mentions in higher-authority sources that will outweigh the problematic ones.
Create dedicated correction content. If AI consistently gets a specific fact wrong, build a page that explicitly addresses it. If ChatGPT keeps saying you don't offer a free plan, create a page titled "Does [Your Brand] Have a Free Plan?" with a clear answer in the first sentence. This gives RAG-based models (like Perplexity and ChatGPT's browsing mode) a definitive source to reference.
Implement an llms.txt file. This emerging standard provides AI-readable brand information in a format designed specifically for language models. Include your correct company description, current product details, and key facts you want AI systems to reference.
Step 4: Use Platform Feedback Mechanisms
While fixing the source layer is most effective long-term, each AI platform also offers direct feedback channels for correcting errors.
ChatGPT: Use the thumbs-down button on inaccurate responses and provide a concise correction with a link to an authoritative source. Prepare brief, factual corrections rather than lengthy explanations. OpenAI reviews flagged content, though response timelines vary.
Claude: Frame corrections as factual inaccuracies through Anthropic's feedback mechanism. When possible, note that the response contains verifiably false information and cite the correct source.
Perplexity: Email their support team with detailed evidence packages. Include the exact query, the wrong output, the correct information, and links to authoritative sources. Perplexity's RAG system can pick up corrections faster than training-based models because it pulls from live web content.
Google AI Overviews: Use the feedback button on AI Overview results. For factual errors about your business, also submit corrections through Google Business Profile and ensure your schema markup provides accurate structured data.
Don't expect instant results from platform feedback alone. Schedule follow-up checks at 7, 14, and 30 days after submission. Platform feedback works best as a supplement to source-level fixes, not a replacement.
Step 5: Build the Positive Signal Layer
Fixing errors is defensive work. Building positive signals is how you shape the narrative going forward. Since 85% of brand mentions in AI responses come from third-party pages, your own website isn't enough.
Target the sources AI actually cites. Don't just pursue any press coverage. Identify which publications AI models reference when discussing your category. Ask ChatGPT and Perplexity your target queries and note which sources they cite. Then pursue mentions specifically from those publications, review sites, and directories.
Build presence on high-citation platforms. Reddit, G2, Capterra, and industry-specific review sites carry outsized weight in AI training data. Claim your profiles on review platforms. Encourage satisfied customers to leave reviews. Participate authentically in relevant Reddit communities. A strong, active presence on platforms AI trusts creates positive signal that outweighs isolated negative mentions.
Publish content that fills gaps. If AI models consistently fail to mention a key product feature or use case, build dedicated content around it. Think of this as creating a knowledge base that both humans and AI systems can reference. The content formats that AI engines prefer to cite (listicles, comparison guides, data-backed explainers) should inform your format choices.
Maintain a steady publishing cadence. AI systems favor fresh content. Citation performance declines within days without updates. The brands with the strongest positive AI presence publish at least two structured content pieces per week and update existing pages quarterly.
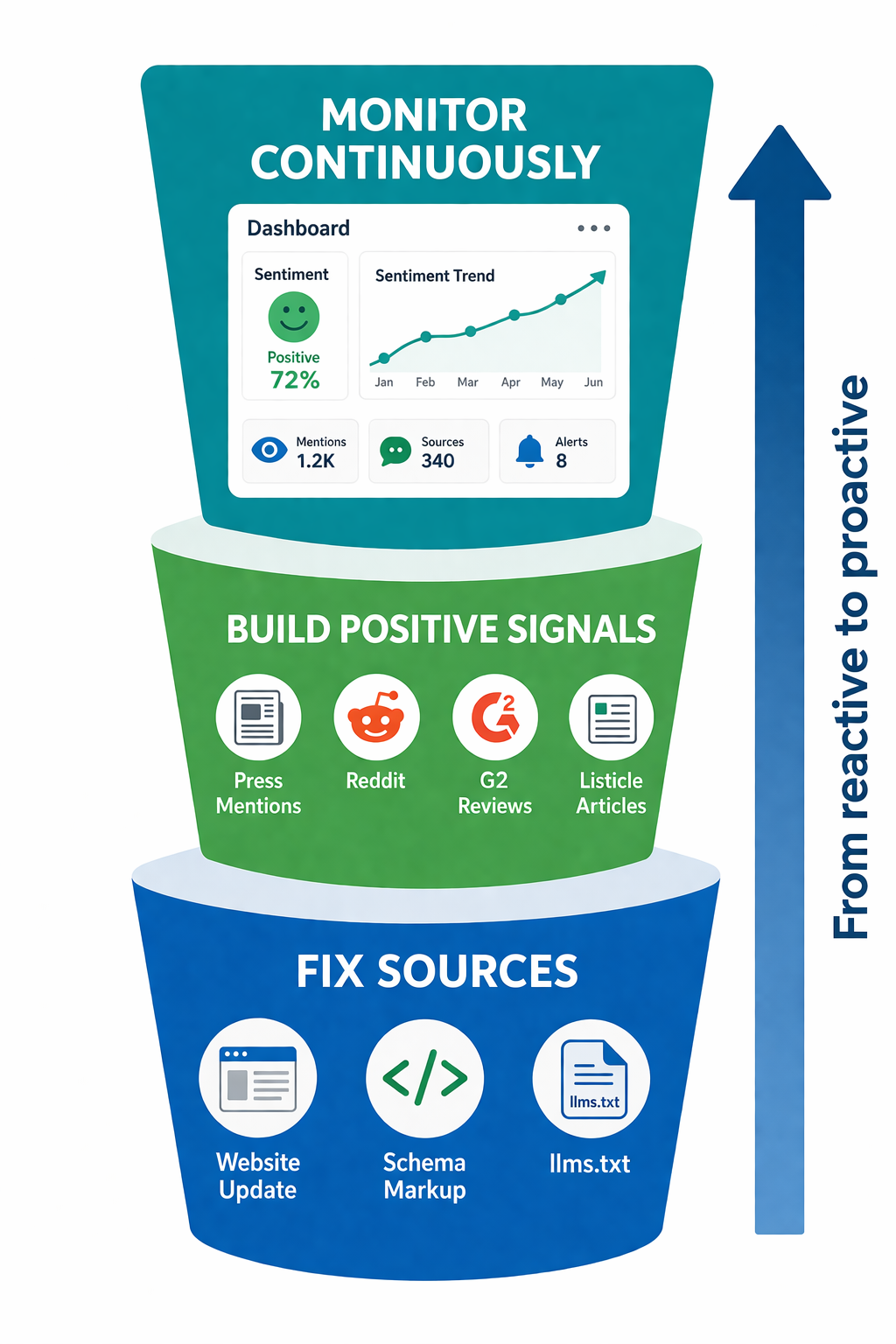
Step 6: Monitor Continuously
AI-generated brand information changes as models retrain on new data, access updated web content, and respond to feedback. What ChatGPT says about you this week may differ next month. One-time fixes aren't enough.
Set up automated monitoring. Manual spot-checks catch obvious problems but miss patterns, regional variations, and gradual sentiment shifts. RepuAI tracks your brand's AI presence across platforms continuously, alerting you to changes in mention frequency, sentiment, or accuracy. The free AI Visibility Checker gives you a quick snapshot to start with.
Track sentiment trends, not just mentions. Being mentioned isn't automatically positive. Monitor whether AI positions your brand favorably, neutrally, or negatively. Track conditional mentions too, such as "good for small teams but lacks enterprise features," which reveal how AI has learned to characterize you.
Compare across platforms. Each AI model may perceive your brand differently. ChatGPT might emphasize one set of strengths while Claude highlights different limitations. These inconsistencies reveal gaps in your content distribution or variations in training data. The differences in how each AI engine cites brands mean you need platform-specific awareness.
Measure the impact of your fixes. After publishing correction content or updating schema, check whether AI responses improve within 2 to 4 weeks. Track citation rates, sentiment scores, and accuracy before and after each intervention. This feedback loop tells you which tactics work best for your specific brand and category.
The Takeaway
AI reputation management isn't a one-time project. It's an ongoing practice that sits alongside traditional SEO, PR, and brand management. The brands that get ahead are the ones treating AI-generated brand information as seriously as they treat Google results, social media presence, and review management.
Start with the audit this week. Run 30 queries across four platforms. Log what you find. Fix the highest-impact errors first by correcting source content, strengthening structured data, and building positive third-party signals. Then set up continuous monitoring so you catch the next issue before your customers do.
In 2026, your brand's reputation isn't just what people find when they search for you. It's what AI tells them before they ever click.



