Как исправить негативные упоминания бренда в ИИ-поиске
Umar
ИИ-движки распространяют неверные цены, выдуманные скандалы и устаревшую информацию о вашем бренде. Пошаговый гайд: как найти, приоритизировать и исправить это

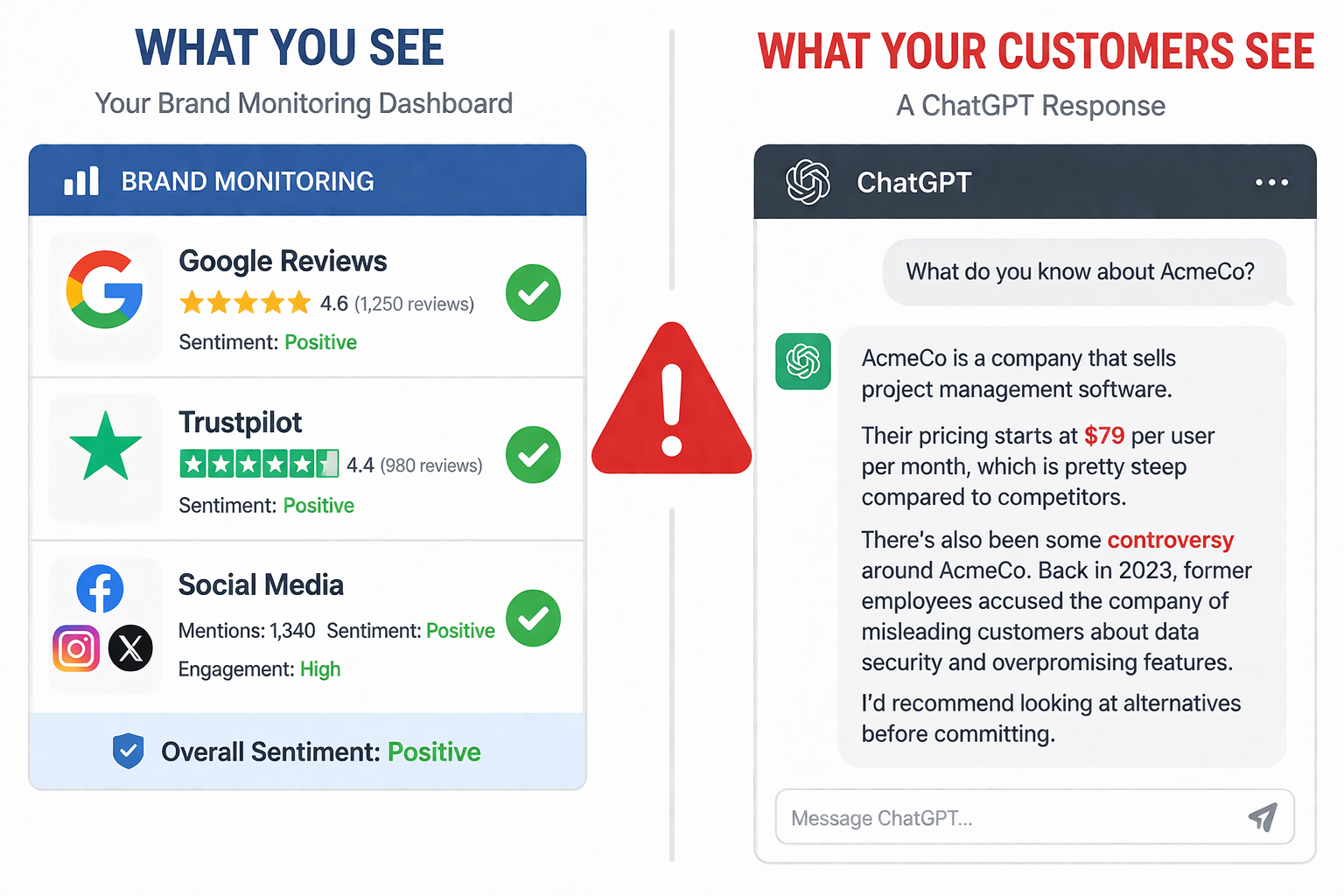
Ваш рейтинг на G2 составляет 4.8 звёзд. Отзывы на Trustpilot отличные. Позиции в Google выглядят сильно. Но прямо сейчас кто-то спрашивает ChatGPT о вашей компании и получает ответ, что у вас произошла утечка данных, которой никогда не было, или что ваш продукт стоит вдвое дороже реальной цены, или что конкурент является «лучшей альтернативой» на основе треда в Reddit от 2023 года.
Самое скверное: вы об этом не знаете. Традиционные инструменты мониторинга отслеживают упоминания в соцсетях, новостные статьи и сайты отзывов. Они не видят, что происходит внутри ИИ-ответов, где всё больше потенциальных клиентов формируют первое впечатление о вашем бренде. По последним данным, 47% маркетологов сталкиваются с ИИ-ошибками о своих брендах несколько раз в неделю. А примерно 1 из 11 ответов ИИ о брендах содержит выдуманную или некорректную информацию.
Это не риск будущего. Это текущая реальность. Этот гайд рассказывает, как находить негативные или неточные ИИ-упоминания, решать, какие исправлять первыми, и системно корректировать их на всех платформах.
Почему традиционное управление репутацией здесь не работает
Если ваш бренд хорошо управляет репутацией, вы, скорее всего, мониторите результаты Google, отвечаете на отзывы и отслеживаете настроения в соцсетях. Это необходимо, но упускает самый быстрорастущий канал формирования восприятия бренда.
ИИ-поиск работает иначе, чем традиционный, и это критически важно для репутации. Когда кто-то гуглит ваш бренд, он видит список ссылок и решает, на что кликнуть. Когда кто-то спрашивает ChatGPT или Perplexity о вашем бренде, он получает единый синтезированный ответ, несущий в себе авторитетный bias. Пользователи воспринимают рекомендации ИИ иначе, чем обычные результаты поиска или мнения в соцсетях. Ответ ИИ становится первым впечатлением, и нет списка альтернативных источников, который бы его уравновесил.
Проблема усугубляется, если учесть, откуда ИИ-модели берут информацию. LLM цитируют Reddit и редакционный контент для более чем 60% информации о брендах, а не корпоративные сайты. Один активный тред на Reddit с жалобами трёхлетней давности может перевесить весь ваш сайт в формировании того, что ChatGPT говорит о вас. Search Engine Land недавно задокументировал случай, когда Google AI Overview вытащил старый форум с жалобами на Reddit о компании, создав негативный нарратив из проблем, решённых несколько лет назад.
Выделяют три типа проблем, с которыми вы можете столкнуться:
ИИ-галлюцинации происходят, когда ИИ уверенно генерирует ложную информацию. Он заявляет выдуманные факты, неправильные цены, несуществующие скандалы или путает бренды (смешивает вас с конкурентом). Эти данные не взяты из реального источника. Модель их выдумала.
ИИ-дезинформация происходит, когда ИИ повторяет устаревшую или предвзятую информацию из обучающих данных. Исходный материал когда-то был точным, но теперь неверен. Ваши цены изменились, продукт эволюционировал, негативная ситуация была разрешена, но ИИ по-прежнему ссылается на старые данные.
Негативное обрамление происходит, когда информация технически точна, но ИИ последовательно позиционирует ваш бренд невыгодно. Он может всегда ставить вас последними, подчёркивать ограничения больше, чем сильные стороны, или представлять конкурентов более позитивно, используя формулировки вроде «лучшая альтернатива».
Каждый тип требует своего подхода к исправлению. Понимание того, с чем вы имеете дело, экономит время.
Шаг 1: Проведите аудит того, что ИИ реально говорит о вас
Вы не можете исправить то, о чём не знаете. Начните с систематического аудита по платформам.
Выполните от 30 до 50 запросов минимум на четырёх платформах. Используйте как минимум ChatGPT, Perplexity, Gemini и Claude. Задавайте вопросы, которые задали бы ваши клиенты: «Что такое [ваш бренд]?», «Можно ли доверять [вашему бренду]?», «[ваш бренд] vs [конкурент]», «лучший [ваша категория] для [задачи]», «какие минусы у [вашего бренда]?» Используйте язык клиентов, а не маркетинговую терминологию.
Повторяйте каждый запрос несколько раз. ИИ выдаёт разные ответы при каждом обращении. Один запрос ничего не покажет. Повторение одного вопроса 3-5 раз выявляет закономерности и показывает, насколько стабильно проявляется проблема.
Фиксируйте всё в таблице. Для каждой проблемы записывайте: платформу, точный запрос, проблемное утверждение, тип проблемы (галлюцинация/дезинформация/обрамление) и оценку серьёзности (высокая/средняя/низкая). Эта таблица станет вашей дорожной картой по исправлениям.
Найдите источник. Для проблем с дезинформацией и обрамлением спросите ИИ: «Какие источники ты использовал для этой информации?» Поищите точную ошибочную формулировку в Google, чтобы найти, откуда ИИ её подхватил. Если одна и та же ошибка появляется на нескольких платформах, она обычно исходит из веб-источника, к которому обе имеют доступ. Если только на одной платформе, она может быть зашита в обучающие данные этой модели.
Для постоянного мониторинга в масштабе такие инструменты, как RepuAI, автоматизируют этот процесс для ChatGPT, Perplexity, Gemini и Claude, отслеживая упоминания, тональность и точность во времени, чтобы вы ловили новые проблемы по мере их появления, а не обнаруживали месяцы спустя.
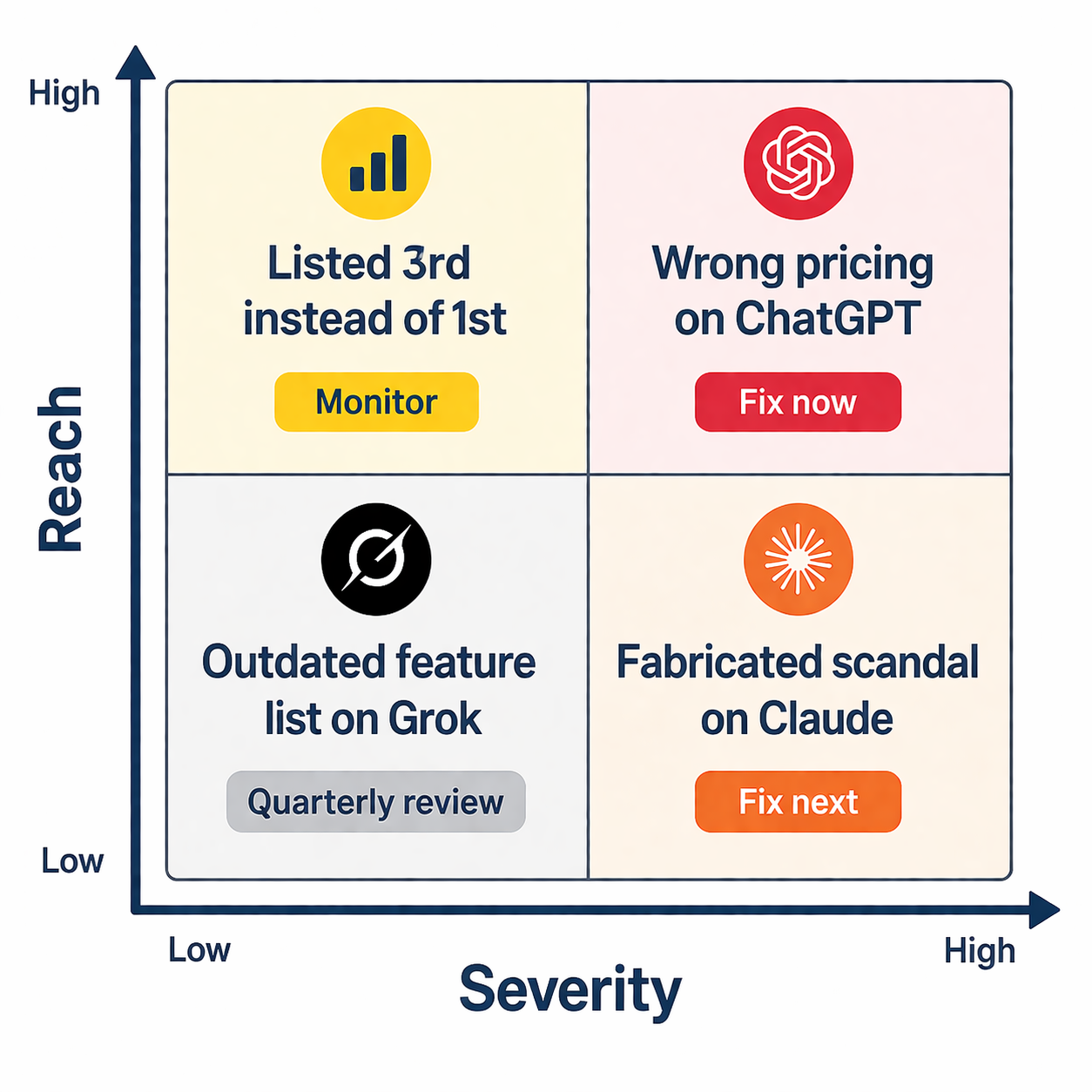
Шаг 2: Расставьте приоритеты по степени влияния
Не каждое негативное упоминание заслуживает одинаковой срочности. Попытка исправить всё сразу размывает усилия. Приоритизируйте по трём факторам:
Охват. Сначала сосредоточьтесь на платформах с наибольшей аудиторией. ChatGPT обрабатывает примерно 77-80% трафика ИИ-поиска. Если ваша главная проблема на ChatGPT, решайте её прежде, чем заниматься менее крупной платформой. Google AI Overviews охватывают 2 миллиарда пользователей ежемесячно, что делает их не менее срочными при появлении неточной информации.
Серьёзность. Выдуманные факты (неправильные цены, несуществующие скандалы, путаница с другим брендом) наносят больше вреда, чем невыгодное обрамление. Клиент, которому сказали, что ваш продукт стоит 500$/месяц, когда реальная цена 50$, никогда не дойдёт до вашей страницы с ценами. Клиент, который видит вас на третьем месте вместо первого, всё же может кликнуть.
Частота. Отслеживайте, насколько стабильно появляется ошибка. Если неверная информация всплывает в 4 из 5 запросов на одну тему, она закрепилась в понимании модели и требует работы на уровне контента. Если в 1 из 5, она может исправиться естественным путём по мере доступа модели к новым источникам.
Создайте простую матрицу приоритетов: проблемы с высоким охватом + высокой серьёзностью + высокой частотой исправляются в первую очередь. Проблемы с низким охватом + низкой серьёзностью + низкой частотой попадают в квартальный обзор.
Шаг 3: Исправьте уровень источников
Наиболее эффективные исправления происходят на уровне источников, а не на уровне ИИ-модели. ИИ-движки синтезируют из веб-контента, поэтому изменение того, что есть в вебе, со временем меняет то, что ИИ говорит о вас.
Обновите свой контент, чтобы он был однозначным. Если ИИ ошибается с вашими ценами, убедитесь, что страница с ценами указывает их чистым, извлекаемым текстом (не запертым в изображениях или JavaScript-виджетах). Если ИИ путает ваш продукт с конкурентом, создайте контент с явным разграничением. Поместите корректную информацию в первые 60 слов каждого релевантного раздела, отформатированную так, чтобы ИИ мог извлечь её как самостоятельный факт. Приёмы структурирования контента из нашего GEO-гайда применимы здесь напрямую.
Усильте structured data. Schema-разметка даёт ИИ-системам машиночитаемые факты о вашем бренде, которые сложнее неверно интерпретировать. Organization-schema с точными свойствами description, foundingDate и knowsAbout помогает ИИ-движкам построить корректный профиль сущности. Product-schema с актуальными price и availability предотвращает ценовые ошибки. Поддерживайте dateModified в актуальном состоянии на каждой странице, чтобы ИИ знал, что ваша информация свежая.
Разберитесь со сторонними источниками, создающими проблемы. Если вы отследили конкретную ошибку до устаревшей сравнительной статьи или треда на Reddit, у вас есть несколько вариантов. Свяжитесь с издателем устаревших статей и попросите исправления или обновления. Ответьте на неточные треды в Reddit фактическими, непромо-коррективами с реального аккаунта. Опубликуйте обновлённый контент на ту же тему с точной информацией. Добейтесь новых упоминаний в более авторитетных источниках, которые перевесят проблемные.
Создайте специальный корректирующий контент. Если ИИ стабильно ошибается в конкретном факте, создайте страницу, которая явно его адресует. Если ChatGPT постоянно утверждает, что у вас нет бесплатного тарифа, создайте страницу «Есть ли у [Вашего Бренда] бесплатный тариф?» с чётким ответом в первом предложении. Это даёт RAG-моделям (таким как Perplexity и режим браузинга ChatGPT) однозначный источник для ссылки.
Внедрите файл llms.txt. Этот формирующийся стандарт предоставляет ИИ-читаемую информацию о бренде в формате, разработанном специально для языковых моделей. Включите в него корректное описание компании, актуальные характеристики продукта и ключевые факты, на которые ИИ-системы должны ссылаться.
Шаг 4: Используйте механизмы обратной связи платформ
Пока исправление на уровне источников наиболее эффективно в долгосрочной перспективе, каждая ИИ-платформа также предлагает каналы прямой обратной связи для коррекции ошибок.
ChatGPT: Используйте кнопку «палец вниз» на неточных ответах и предоставьте краткое исправление со ссылкой на авторитетный источник. Готовьте краткие, фактические коррективы, а не длинные объяснения. OpenAI рассматривает отмеченный контент, хотя сроки реагирования варьируются.
Claude: Оформите коррекцию как фактическую неточность через механизм обратной связи Anthropic. По возможности отметьте, что ответ содержит проверяемо ложную информацию, и укажите корректный источник.
Perplexity: Напишите их службе поддержки с подробным пакетом доказательств. Включите точный запрос, ошибочный ответ, корректную информацию и ссылки на авторитетные источники. RAG-система Perplexity может подхватывать исправления быстрее, чем модели на основе обучения, потому что она берёт данные из живого веб-контента.
Google AI Overviews: Используйте кнопку обратной связи на результатах AI Overview. Для фактических ошибок о вашем бизнесе также подайте коррекцию через Google Business Profile и убедитесь, что ваша schema-разметка содержит точные structured data.
Не ждите мгновенных результатов только от обратной связи платформ. Запланируйте контрольные проверки на 7, 14 и 30 день после подачи. Обратная связь с платформами лучше всего работает как дополнение к исправлениям на уровне источников, а не как их замена.
Шаг 5: Выстройте слой позитивных сигналов
Исправление ошибок это оборонительная работа. Выстраивание позитивных сигналов формирует нарратив на будущее. Поскольку 85% упоминаний брендов в ИИ-ответах приходят со сторонних страниц, вашего собственного сайта недостаточно.
Нацельтесь на источники, которые ИИ реально цитирует. Не гонитесь за любым пресс-покрытием. Определите, какие издания ИИ-модели используют при обсуждении вашей категории. Задайте ChatGPT и Perplexity целевые запросы и отметьте, какие источники они цитируют. Затем добивайтесь упоминаний именно в этих изданиях, на сайтах отзывов и в каталогах.
Выстройте присутствие на платформах с высоким уровнем цитирования. Reddit, G2, Capterra и отраслевые сайты отзывов несут непропорционально большой вес в обучающих данных ИИ. Заберите свои профили на площадках отзывов. Поощряйте довольных клиентов оставлять отзывы. Участвуйте аутентично в релевантных сообществах Reddit. Сильное, активное присутствие на платформах, которым ИИ доверяет, создаёт позитивный сигнал, перевешивающий изолированные негативные упоминания.
Публикуйте контент, который заполняет пробелы. Если ИИ-модели стабильно не упоминают ключевую функцию продукта или сценарий использования, создайте контент вокруг него. Воспринимайте это как базу знаний, на которую могут ссылаться и люди, и ИИ-системы. Форматы контента, которые ИИ-поисковики предпочитают цитировать (подборки, сравнительные гайды, материалы с данными), должны определять ваш выбор формата.
Поддерживайте стабильную периодичность публикаций. ИИ-системы предпочитают свежий контент. Эффективность цитирования снижается за считанные дни без обновлений. Бренды с самым сильным позитивным ИИ-присутствием публикуют не менее двух структурированных материалов в неделю и обновляют существующие страницы ежеквартально.
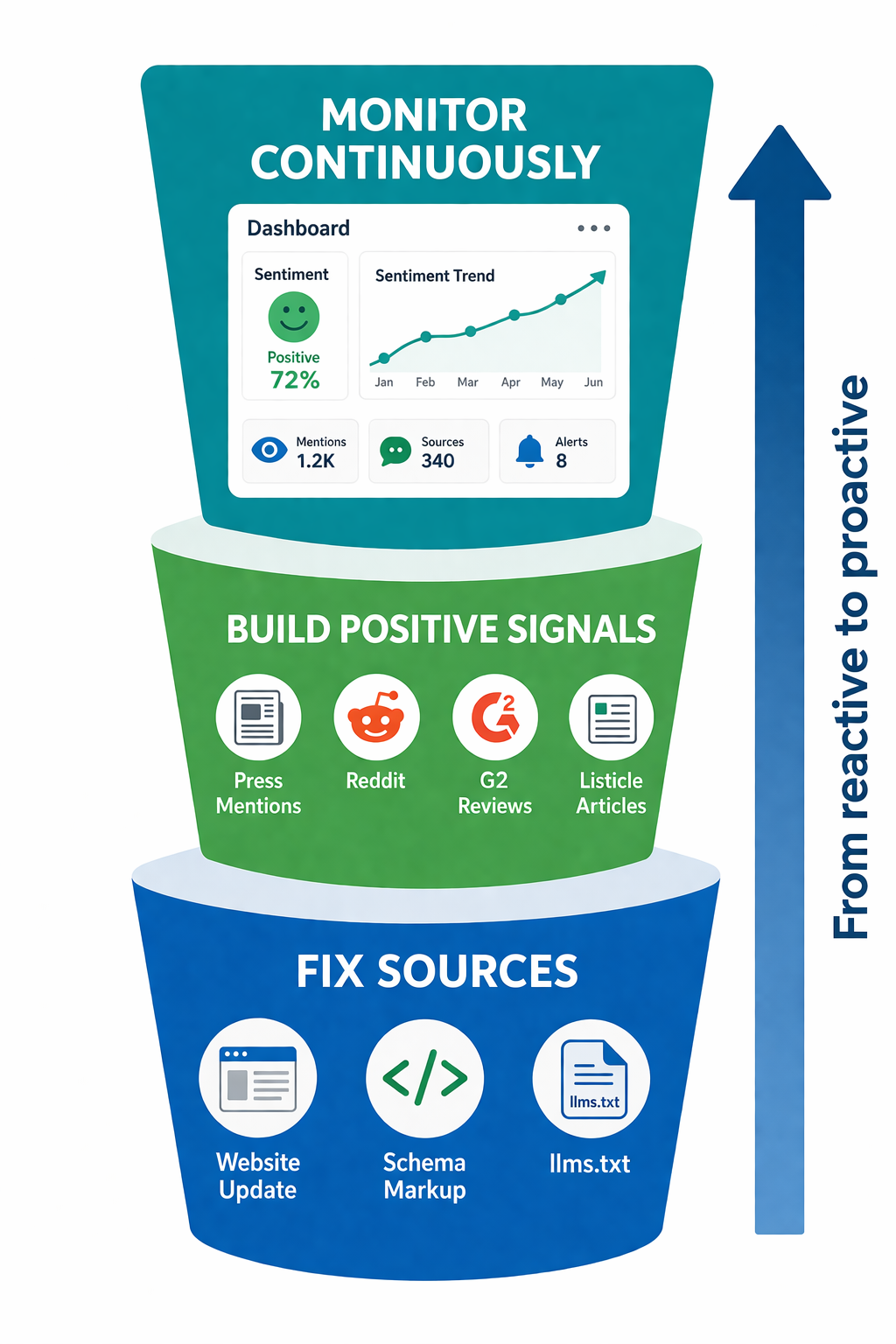
Шаг 6: Мониторьте непрерывно
ИИ-информация о бренде меняется по мере того, как модели переучиваются на новых данных, получают доступ к обновлённому контенту и реагируют на обратную связь. То, что ChatGPT говорит о вас на этой неделе, может измениться через месяц. Разовых исправлений недостаточно.
Настройте автоматический мониторинг. Ручные проверки ловят очевидные проблемы, но упускают паттерны, региональные различия и постепенные сдвиги тональности. RepuAI непрерывно отслеживает ИИ-присутствие вашего бренда на всех платформах, оповещая об изменениях в частоте упоминаний, тональности или точности. Бесплатный AI Visibility Checker даёт быстрый снимок для начала.
Отслеживайте тренды тональности, а не просто упоминания. Быть упомянутым не означает автоматически позитив. Мониторьте, позиционирует ли ИИ ваш бренд выгодно, нейтрально или негативно. Отслеживайте и условные упоминания, такие как «хорош для малых команд, но не тянет enterprise-задачи», которые раскрывают, как ИИ научился характеризовать вас.
Сравнивайте по платформам. Каждая ИИ-модель может воспринимать ваш бренд по-разному. ChatGPT может подчёркивать одни сильные стороны, а Claude выделять другие ограничения. Эти расхождения выявляют пробелы в дистрибуции контента или различия в обучающих данных. Различия в том, как каждый ИИ-движок цитирует бренды, означают, что вам нужна осведомлённость по каждой платформе отдельно.
Измеряйте эффект исправлений. После публикации корректирующего контента или обновления schema проверяйте, улучшились ли ИИ-ответы в течение 2-4 недель. Отслеживайте частоту цитирования, оценки тональности и точность до и после каждого вмешательства. Этот цикл обратной связи покажет, какие тактики лучше всего работают для вашего бренда и категории.
Главный вывод
Управление ИИ-репутацией не разовый проект. Это постоянная практика, которая стоит в одном ряду с традиционным SEO, PR и бренд-менеджментом. Выигрывают те бренды, которые относятся к ИИ-информации о себе так же серьёзно, как к результатам Google, присутствию в соцсетях и управлению отзывами.
Начните с аудита на этой неделе. Выполните 30 запросов на четырёх платформах. Зафиксируйте, что найдёте. Исправьте проблемы с максимальным влиянием в первую очередь, корректируя контент источников, усиливая structured data и выстраивая позитивные сторонние сигналы. Затем настройте непрерывный мониторинг, чтобы ловить следующую проблему раньше, чем это сделают ваши клиенты.
В 2026 году репутация вашего бренда определяется не только тем, что люди находят, когда ищут вас. Но и тем, что ИИ говорит им до того, как они вообще кликнут.



