Schema-разметка для AI-видимости: что реально работает в 2026 году
Umar
Какие типы schema помогают вашему контенту попасть в ответы ИИ в 2026 году. Практический гайд с примерами JSON-LD, чеклистом аудита и данными о том, что работает

Шестьдесят пять процентов страниц, которые цитирует AI Mode от Google, содержат structured data. Для ChatGPT эта цифра составляет 71%. Эти два числа объясняют, почему schema-разметка за неполный год превратилась из приятного SEO-бонуса в техническую основу AI-видимости.
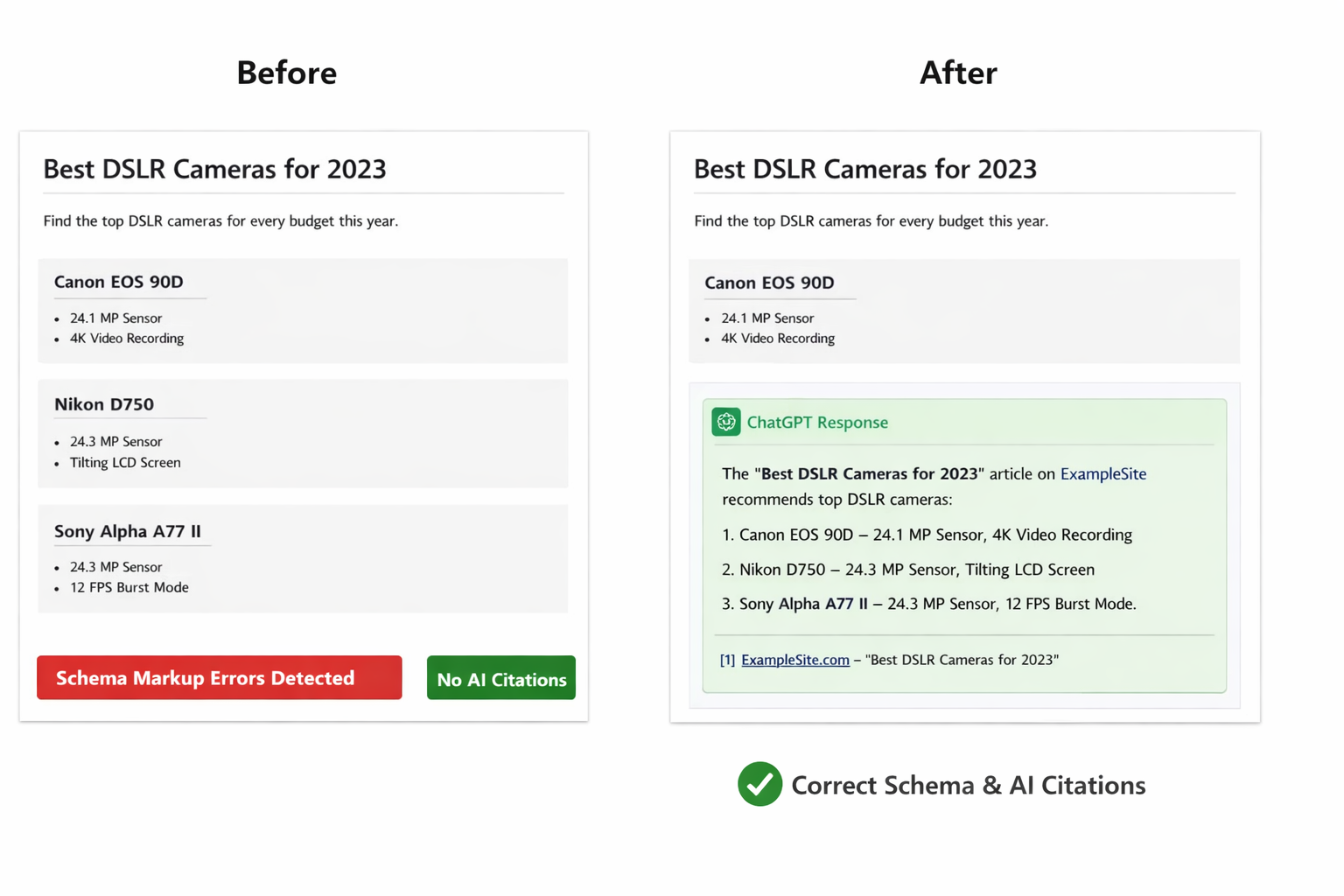
Но есть нюанс. Google отключил FAQ-schema в январе 2026, а HowTo-schema в феврале. Мартовское обновление ядра 2026 года перекроило то, как structured data влияет на ранжирование и AI-цитирование. А контролируемый эксперимент, опубликованный на Search Engine Land, показал, что в AI Overviews попали только страницы с качественно реализованной schema, тогда как страницы с небрежной разметкой не получили ничего, несмотря на ранжирование по большему числу ключевых слов.
Schema по-прежнему работает. Плохо сделанная schema не работает. Этот гайд рассказывает, какие типы schema действительно важны для AI-видимости прямо сейчас, как каждая крупная ИИ-платформа использует structured data и как провести аудит и внедрение, не тратя время на устаревшие фичи.
Почему schema для ИИ важнее, чем для традиционного SEO
Традиционное SEO использовало schema в основном для получения расширенных результатов: звёзд рейтинга, карточек рецептов, FAQ-дропдаунов. Эти визуальные улучшения были полезными, но необязательными. Страница могла отлично ранжироваться и без structured data.
ИИ-поиск устроен иначе. Когда ChatGPT, Perplexity или AI Mode от Google генерируют ответ, им нужно понять, о чём страница, кто её опубликовал, насколько актуальна информация и можно ли доверять источнику. Часть этого можно извлечь из простого текста. Но structured data убирает неоднозначность.
Представьте: страница, упоминающая «Apple», может быть о компании, о фрукте, об Apple Music или Apple TV. Organization-schema со свойством sameAs, ссылающимся на страницу компании в Википедии и официальные соцсети, точно сообщает ИИ-системам, о какой сущности идёт речь. Без этого сигнала ИИ вынужден угадывать и часто переключается на источник, где ответ проще.
И Google, и Microsoft подтвердили в марте 2025, что используют schema-разметку в своих генеративных ИИ-функциях. ChatGPT также подтвердил, что structured data влияет на то, какие продукты появляются в его ответах. Это не предположение о будущем использовании. Это подтверждённая инфраструктура.
Роль schema сместилась от «триггера отображения» к «сигналу доверия». ИИ-системы используют её для проверки фактов, разрешения сущностей и оценки того, достаточно ли ваш контент надёжен для цитирования. Это принципиально другая ценность по сравнению со звёздочками рейтинга в выдаче.
Что изменилось в начале 2026 года
Три обновления перекроили ландшафт schema:
Google отключил расширенные результаты FAQ и HowTo. FAQ-schema перестала генерировать расширенные результаты в январе 2026. HowTo последовала в феврале. Это вызвало путаницу: некоторые команды полностью удалили разметку. Это ошибка. Документация Google уточнила, что ИИ-системы по-прежнему обрабатывают эти данные, даже без визуальной SERP-фичи. Schema по-прежнему помогает ИИ понять структуру контента. Просто она больше не создаёт выпадающий блок в результатах поиска. (Это похоже на то, как работает llms.txt: сигнал, который помогает ИИ-краулерам обрабатывать ваш сайт, даже если видимый эффект не всегда мгновенный.)
Мартовское обновление ядра 2026 сместило роль schema. Review-schema на редакционных сравнительных статьях была массово понижена. Но страницы с чистой, точной entity-schema показали улучшение частоты цитирования в AI Mode от Google. Обновление наказало раздутую или несоответствующую schema и вознаградило разметку, которая реально описывала содержимое страницы.
Свойство knowsAbout набрало вес. После марта 2026 Organization- и Person-schema с объявлениями knowsAbout стали более влиятельными. Указание тем, в которых ваша организация реально обладает экспертизой, помогает AI Mode отбирать ваш контент для запросов в этих областях. Organization-schema, заявляющая экспертизу в «контент-маркетинге» и «оптимизации под ИИ-поиск», с большей вероятностью будет процитирована по этим темам, чем schema без тематических объявлений.
Общее направление очевидно: ИИ-системы вознаграждают schema, которая точна, конкретна и ориентирована на сущности. Они игнорируют или штрафуют schema, которая раздута, устарела или не соответствует видимому контенту.
Четыре типа schema, которые влияют на AI-цитирование
После отключений четыре основных типа schema несут наибольший вес для AI-видимости. Всё остальное опционально или ситуативно.
Organization Schema
Это фундамент. Organization-schema утверждает ваш бренд как распознаваемую сущность в графах знаний всех платформ. Она должна быть на каждой странице вашего сайта.
Что включить помимо базового: name, url, logo, description, sameAs (ссылки на вашу страницу в Википедии, LinkedIn, соцсети), contactPoint, foundingDate, areaServed и недавно ставшее важным свойство knowsAbout.
Ссылки sameAs критически важны. Именно через них ИИ-системы связывают ваш сайт с более широким графом знаний. Если у вашей компании есть страница в Википедии, запись в Wikidata или верифицированные профили в LinkedIn и Crunchbase, их указание в sameAs даёт ИИ-системам подтверждение сущности, необходимое для доверия к вашему контенту.
Сайты с развёрнутой Organization-schema цитируются чаще, потому что ИИ-движки могут уверенно атрибутировать информацию верифицированной сущности, а не анонимному источнику.
Article / BlogPosting Schema
Article-schema сообщает ИИ-системам, какой тип контента содержит страница, кто его написал, когда он был опубликован и когда последний раз обновлён. Эта классификация помогает ИИ соотнести вашу страницу с интентом запроса при отборе источников.
Самое важное свойство, которое большинство команд упускает: dateModified. ИИ-движки активно используют его как сигнал актуальности. Если вы обновили пост, но не обновили dateModified, ИИ по-прежнему считает ваш контент устаревшим. Один практик рассказал, что забытое обновление этого единственного поля приводило к тому, что ИИ-движки неделями продолжали цитировать устаревшую информацию со страницы клиента.
Включите author с привязанной Person-schema (не просто строку с именем), publisher со ссылкой на вашу Organization-schema, headline, description, datePublished и dateModified. Используйте свойство @id для связи Article-schema с вашими Organization- и Person-сущностями.
Product Schema
Для любого бизнеса, продающего товары или услуги, Product-schema сообщает ИИ-системам, что именно вы предлагаете: название, описание, бренд, SKU, цену, наличие и рейтинг покупателей. Шопинг-функции ChatGPT и ИИ-шопинг-агенты в значительной мере полагаются на эти данные при формировании рекомендаций.
Страницы с полной Product-schema (включая цену, рейтинг и наличие) получают рост CTR на 74,1% в традиционном поиске. В ИИ-поиске влияние ещё более прямое: если ИИ-агент не может подтвердить вашу цену или наличие через structured data, он не станет рисковать с рекомендацией.
Включите offers с price, priceCurrency и availability. Добавьте aggregateRating, если есть отзывы. Укажите brand, sku и gtin для однозначной идентификации товара. Чем полнее и точнее ваша Product-schema, тем увереннее ИИ-системы смогут рекомендовать ваши продукты.
Review / AggregateRating Schema
Отзывы и рейтинги покупателей остаются мощными сигналами доверия для ИИ-систем. Когда ИИ нужно порекомендовать «лучший» вариант в категории, он ищет агрегированные данные отзывов для подкрепления рекомендации.
После марта 2026 ключевое правило: Review-schema должна размещаться на страницах товаров или услуг, а не на редакционных сравнительных статьях. Google активно понижал редакционные страницы, использующие Review-schema для накрутки отображения. Оставляйте Review и AggregateRating на страницах с реальными отзывами покупателей.

Как каждая ИИ-платформа использует schema
Не каждый ИИ-движок обрабатывает structured data одинаково. Понимание различий помогает расставить приоритеты.
Google AI Overviews и AI Mode имеют самую прямую связь с schema. Google подтвердил, что structured data «критически важна для современных поисковых функций». Отбор источников в AI Mode учитывает качество schema наряду с PageRank, актуальностью и сигналами контента. Качественно реализованная schema с чистым разрешением сущностей ведёт к более высоким оценкам доверия.
ChatGPT обрабатывает structured data, когда его режим браузинга извлекает веб-контент. Когда ChatGPT обращается к странице с Organization- или Article-schema, он извлекает детали сущности из структурированных свойств. Для товарных рекомендаций ChatGPT проверяет Product-schema на цену, наличие и рейтинг перед включением бренда в шопинг-ответы.
Perplexity напрямую сканирует веб и использует schema для разрешения неоднозначности источников. Когда несколько страниц обсуждают похожие темы, Perplexity использует Organization- и Article-schema, чтобы определить, какой источник является наиболее авторитетным оригинальным издателем, а не агрегатором.
Claude обрабатывает контент страниц похожим образом, но придаёт больше веса качеству и глубине видимого текста. Schema выступает дополнительным сигналом доверия, а не основным фактором ранжирования.
Практический вывод: внедрите schema один раз в формате JSON-LD, и она будет работать на всех платформах. Платформо-специфичные реализации не нужны. Но отдача различается: Google AI Mode и ChatGPT показывают наиболее сильный отклик на качество structured data.
Практический чеклист аудита schema
Прежде чем добавлять новую schema, проведите аудит того, что уже есть. На многих сайтах разметка сломана, устарела или не соответствует контенту, что активно вредит вместо того, чтобы помогать.
Неделя 1: Оцените текущее состояние
Проверьте топ-20 страниц через Google Rich Results Test. Ищите ошибки валидации, отсутствующие обязательные поля и предупреждения. Просмотрите раздел «Улучшения» в Google Search Console на предмет ошибок schema по всему сайту. Отметьте, на каких страницах есть schema, а на каких нет.
Неделя 2: Исправьте проблемы с точностью
Сравните заявления вашей schema с видимым контентом страницы. Совпадает ли dateModified с реальной датой последнего обновления? Ссылается ли author на реального человека с биографией на сайте? Совпадает ли price в Product-schema с фактической ценой на странице? Расхождения между schema и видимым контентом тихо убивают цитирование. ИИ-системы проверяют это, и несоответствия снижают доверие.
Неделя 3: Внедрите базовую schema
Добавьте Organization-schema на весь сайт, если её ещё нет. Добавьте Article/BlogPosting-schema на каждую контентную страницу. Добавьте Product-schema на страницы товаров и услуг. Используйте JSON-LD в секции <head> каждой страницы. Свяжите сущности через свойство @id, чтобы ваши Organization-, Person- и Article-schema ссылались друг на друга.
Неделя 4: Мониторинг и итерации
Эффект schema на AI-видимость обычно проявляется через 2-4 недели, по мере того как ИИ-системы пересканируют ваш контент. Отслеживайте изменения частоты AI-цитирования через RepuAI, чтобы увидеть, выросли ли упоминания вашего бренда в ChatGPT, Perplexity, Gemini и Claude после внедрения. Сравните показатели AI-видимости до и после с помощью бесплатного AI Visibility Checker. В Search Console следите за изменениями в показах расширенных результатов и новыми ошибками schema.
Частые ошибки, которые убивают AI-цитирование
Внедрение schema один раз без последующих обновлений. Свойство dateModified критически важно для сигналов актуальности. Каждый раз при обновлении контента обновляйте dateModified. Установите минимальную периодичность аудита раз в квартал.
Schema, которая противоречит видимому контенту. Если ваша schema говорит «Обновлено в марте 2026», а видимая страница по-прежнему показывает данные 2024 года, ИИ-системы это замечают. Автоматизированные системы, которые берут данные schema из того же источника, что и контент страницы, предотвращают такое расхождение.
Нагромождение слишком многих типов schema на одной странице. Стопка Article + FAQ + HowTo + Product schema на одной странице создаёт шум. Используйте основной тип schema, соответствующий главному назначению страницы. Статья получает Article-schema. Страница товара получает Product-schema. Не пытайтесь заставить одну страницу служить всем целям schema одновременно.
Использование общих значений author. Поле author в schema со значением «Admin» или «Редакция» даёт нулевой сигнал доверия. Привяжите Person-schema с реальным именем, биографией, квалификацией и свойствами sameAs, указывающими на LinkedIn или профессиональные профили автора. ИИ-системы придают больший вес контенту от идентифицируемых экспертов, чем от анонимных источников.
Игнорирование sameAs для разрешения сущностей. Без ссылок sameAs ИИ-системы не могут уверенно связать ваш сайт с вашим присутствием в более широком графе знаний. Это единственное свойство, которое проводит границу между верифицированной сущностью и неизвестным доменом.
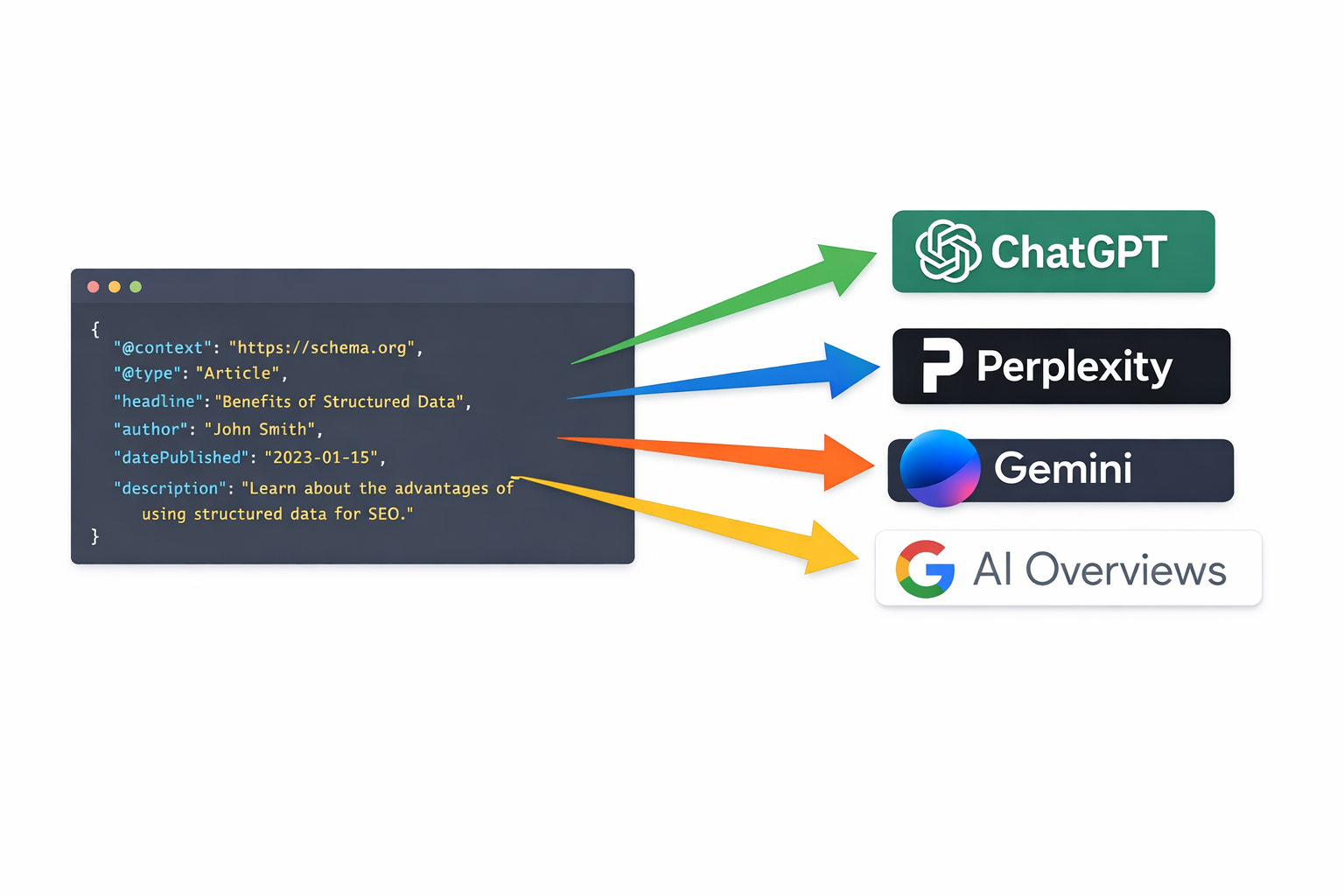
JSON-LD: единственный формат, который стоит использовать
Существуют три формата structured data: Microdata, RDFa и JSON-LD. Используйте JSON-LD. Это формат, который Google официально рекомендует, и каждый крупный ИИ-движок обрабатывает его наиболее надёжно.
JSON-LD размещается в отдельном блоке <script> в <head> вашей страницы, чисто отделённый от HTML. Это важно, потому что ИИ-краулеры могут парсить его без помех от вёрстки и динамического контента. Microdata и RDFa встраивают schema внутрь HTML-элементов, что создаёт конфликты парсинга и усложняет обновления.
Если вы используете CMS вроде WordPress, плагины типа Yoast SEO или Rank Math генерируют базовый JSON-LD автоматически. Для более продвинутых реализаций кастомный JSON-LD в шаблоне хедера даёт полный контроль. Ключевое требование: разметка должна совпадать с реальным контентом на странице. Без исключений.
Место schema в вашей AI-стратегии
Одна лишь schema не сделает вас видимыми для ИИ-движков. Контролируемое исследование не нашло корреляции между покрытием schema и частотой цитирования, когда другие факторы вроде качества контента и тематической авторитетности не контролировались. Schema необходимый технический фундамент, но лучше всего она работает в сочетании со стратегиями контента, описанными в гайде о том, какой контент цитируют ИИ-поисковики, и фреймворком оптимизации из практического гайда по GEO.
Представьте это как слои. Технический слой (schema, сканируемость, рендеринг) делает контент доступным для ИИ. Контентный слой (структура, ясность, оригинальные данные, экспертная атрибуция) делает его достойным цитирования. Слой авторитетности (обратные ссылки, упоминания третьими сторонами, сигналы бренда) делает его заслуживающим доверия. Schema покрывает первый слой. Вам по-прежнему нужны два других.
Если вы уже разобрались с фреймворком SEO, AEO и GEO, schema находится точно в зоне пересечения, где выигрывают все три дисциплины. Правильная structured data помогает вам ранжироваться (SEO), быть выбранным в качестве прямого ответа (AEO) и получать цитирование от ИИ (GEO) одновременно.
Для брендов, которые только начинают: внедрите Organization- и Article-schema на весь сайт на этой неделе. Добавьте Product-schema на ключевые коммерческие страницы. Поставьте напоминание в календарь обновлять dateModified каждый раз при обновлении контента. А потом начните отслеживать, растёт ли частота AI-цитирования. Данные подскажут, куда двигаться дальше.