AI Crawlers Explained: GPTBot, ClaudeBot, and Your Robots.txt
Umar
GPTBot, ClaudeBot, and PerplexityBot hit your site daily, but most brands don't know which to allow. A practical 2026 guide with templates and brand visibility data

There's a file on your server that quietly decides whether ChatGPT, Claude, Perplexity, and Gemini can read your website. It's called robots.txt, and for most companies it hasn't been updated since 2023. That's a problem, because the AI crawler landscape in 2026 looks nothing like it did two years ago.
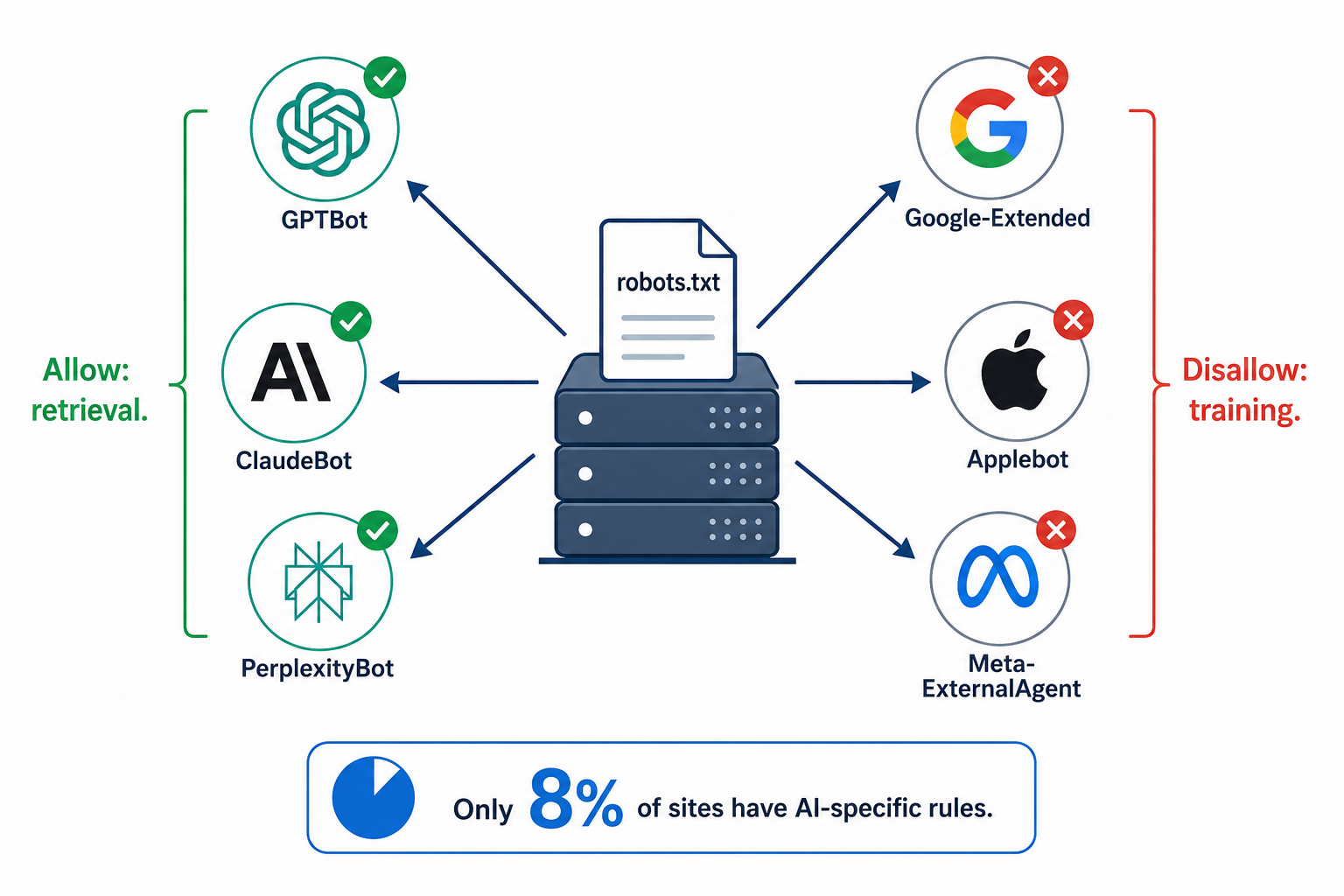
OpenAI now runs three separate crawlers. Anthropic runs three. Google separates AI training from regular search indexing. Applebot surged 140% in a single month and is now the sixth-largest AI bot globally. Meanwhile, only 8% of the top 10,000 domains have any AI-specific rules in their robots.txt at all. The rest are running on defaults that may be silently blocking AI engines from reading their content, or giving every AI company unrestricted access to everything.
This guide covers the specific bots that matter for brand visibility, the difference between training and retrieval crawlers (a distinction most marketers don't know exists), and how to configure your robots.txt to maximize AI citations without giving away training data.
Training Bots vs. Retrieval Bots: The Distinction That Changes Everything
The biggest mistake companies make with AI crawlers is treating them as a single category. In 2026, every major AI provider operates at least two types of crawlers, and the difference between them has direct implications for your brand visibility.
Training crawlers collect content to build and improve AI models. They scrape large volumes of pages to feed into the next model update. When you block a training crawler, your content stops being encoded into the model's weights during future training. The AI gradually "forgets" your brand's current information as its knowledge becomes stale.
Retrieval crawlers fetch specific pages in real time when a user asks an AI tool a question. They power the live search features in ChatGPT, Claude, and Perplexity. When you block a retrieval crawler, your pages are excluded from AI search results immediately, even if the model already has some training-based knowledge of your brand.
This matters enormously for the decision you make. Blocking training crawlers is a reasonable choice if you want to protect proprietary content from being absorbed into model weights. Blocking retrieval crawlers kills your AI search visibility right now. A Q1 2026 Cloudflare analysis found that 89.4% of all AI crawler traffic serves training or mixed purposes, while only 8% is search-related. The retrieval bots are low-volume but high-impact for your brand.
The practical takeaway: you can block training and allow retrieval. This is the most popular strategy in 2026, and it protects your content from model training while keeping your brand visible in AI search answers. But you need to know which bots belong to which category.
Every AI Crawler That Matters in 2026
Here's the complete list of crawlers you need rules for, organized by provider and purpose.
OpenAI (ChatGPT)
OpenAI runs three crawlers, each with independent robots.txt rules. Blocking one doesn't affect the others.
GPTBot is the training crawler. It collects content to improve OpenAI's models. GPTBot is the most aggressive AI crawler in the wild, hitting sites at a median of 4,200 requests per day (2-4x more than any other AI bot, per a 30-day server log study across 12 production sites). It revisits high-traffic pages every 2.4 days. GPTBot is also the most blocked AI crawler globally, disallowed by more domains than any other AI bot.
OAI-SearchBot is the search indexer. It crawls to build the index that powers ChatGPT's search feature. Blocking GPTBot does not block OAI-SearchBot. Many sites now allow OAI-SearchBot while blocking GPTBot, getting their content into ChatGPT search results without contributing to future training.
ChatGPT-User is the real-time retrieval bot. It fires when a ChatGPT user asks the model to browse a specific URL or perform a live web search. Blocking this bot means ChatGPT literally can't read your page when a user asks about you. PerplexityBot and ChatGPT-User appear more in ALLOW rules than DISALLOW across Cloudflare's dataset, because site owners recognize they drive referral traffic.
Anthropic (Claude)
Anthropic mirrors OpenAI's three-bot structure, formally documented in February 2026.
ClaudeBot is the training crawler. It feeds Anthropic's model pre-training corpus. ClaudeBot trails GPTBot in volume at about 1,800 hits per site per day. Its crawl-to-refer ratio is striking: ClaudeBot reads 20,583 pages for every single referral it sends back to publishers (compared to OpenAI's 1,255:1 ratio). ClaudeBot overtook CCBot in April 2026 to become the second most blocked AI bot by raw count.
Claude-User is the user-initiated fetcher that runs when a Claude user asks the model to analyze a specific page. Blocking this removes your content from real-time Claude conversations.
Claude-SearchBot indexes content to improve Claude's search result quality. It's separate from training and separate from user-initiated fetching.
Google-Extended controls whether Google uses your content for Gemini model training. Critically, blocking Google-Extended does not affect Google Search rankings or AI Overviews. AI Overviews use the standard Googlebot. Google-Extended specifically controls Gemini training only.
Others
PerplexityBot powers Perplexity's AI search engine. It's quieter than GPTBot (about 980 hits per day) but spikes when queries about your brand or category go viral. Blocking it removes you from Perplexity answers entirely.
Meta-ExternalAgent quietly became the #2 AI crawler at 16.3% of traffic, overtaking both ClaudeBot and GPTBot. It feeds Meta AI across Facebook, Instagram, and WhatsApp. Only 3.3% of domains reference it in robots.txt, making it the crawler with the largest gap between traffic share and blocking activity.
Applebot-Extended surged 140% in one month (from 2.97% to 7.15% of AI traffic) and is now closing in on GPTBot's share. If you've been ignoring Apple's crawler, you're missing one of the fastest-growing AI bots in the landscape.
Bytespider (ByteDance) has a documented history of not respecting robots.txt. If you want to block it, you'll need server-level rules, not just a robots.txt entry.

Three Ready-to-Use Robots.txt Templates
Rather than explaining theory, here are three templates for the most common scenarios. Pick the one that matches your situation and adapt it.
Template 1: Maximum AI Visibility
Best for: B2B SaaS, agencies, service businesses, anyone who wants AI to recommend them. This allows every major AI crawler full access.
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: Applebot-Extended
Allow: /
User-agent: Meta-ExternalAgent
Allow: /
Template 2: Block Training, Allow Retrieval
Best for: publishers, content creators, companies with proprietary data who still want AI search visibility. This is the most popular strategy in 2026.
# Block training crawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
# Allow retrieval/search crawlers
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Applebot-Extended
Allow: /
Template 3: Selective Access by Content Type
Best for: companies with mixed public and proprietary content. Allows AI access to your blog and marketing pages while blocking product documentation or gated resources.
User-agent: GPTBot
Allow: /blog/
Allow: /about/
Allow: /pricing/
Disallow: /docs/
Disallow: /api/
Disallow: /admin/
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
Disallow: /admin/
Disallow: /api/
Apply the same path-level logic to ClaudeBot, Claude-User, and PerplexityBot based on your needs.
The Cloudflare Trap
If your site uses Cloudflare (and over 20% of all websites do), there's a catch most teams don't know about. Cloudflare's "AI Scrapers and Crawlers" toggle in the Security dashboard blocks AI bots at the WAF layer, before robots.txt is ever consulted. Your robots.txt can say "Allow: /" for every AI crawler, and Cloudflare silently blocks them all.
One documented case found that PerplexityBot and ClaudeBot were being rejected by Cloudflare for months while the site's robots.txt was correctly configured. After disabling the Cloudflare AI block, both crawlers appeared in server logs within 48 hours, and AI-sourced referral traffic began within six weeks.
Check your Cloudflare dashboard under Security > Bots. Look for the "AI Scrapers and Crawlers" managed rule. If it's enabled, it overrides everything in your robots.txt. For granular per-bot control, use Cloudflare's AI Crawl Control feature instead.
How Robots.txt Connects to Your Broader AI Strategy
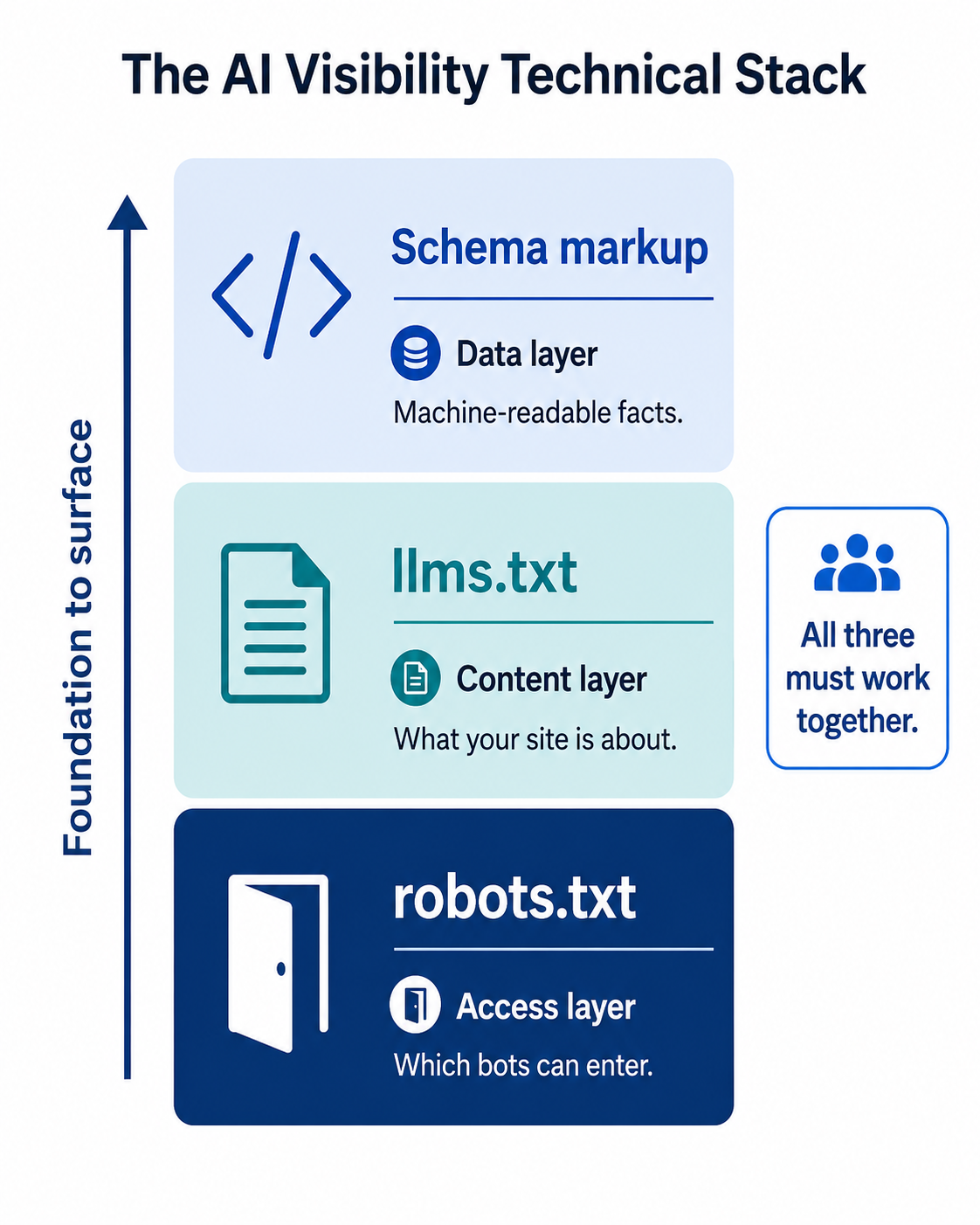
Robots.txt is the access layer. It determines whether AI crawlers can even read your content. But access alone doesn't make you visible. It connects to two other technical components you should implement together.
llms.txt is the content layer. While robots.txt controls which bots can enter, llms.txt tells AI systems what your site is about in a format designed specifically for language models. Think of robots.txt as the door and llms.txt as the welcome mat with instructions. If you've implemented llms.txt but your robots.txt blocks the crawlers that would read it, you've built a welcome mat nobody can see.
Schema markup is the data layer. Structured data gives AI systems machine-readable facts about your brand, products, and content. But if the crawlers can't access the pages with your schema, the structured data never gets processed. 65% of pages cited by Google's AI Mode include structured data, and 71% of pages cited by ChatGPT do. Those pages need to be accessible to the relevant crawlers first.
The three work as a stack: robots.txt (access) > llms.txt (format) > schema (data). Getting one right without the others leaves gaps. If you've followed RepuAI's guides on schema implementation and getting cited by ChatGPT, checking your robots.txt is the foundation that makes those tactics work.
A Practical Audit Checklist
Before making changes, audit your current setup:
1. Check your robots.txt. Visit yourdomain.com/robots.txt in a browser. Look for any User-agent: * with Disallow: / rules, which block all crawlers including AI bots. Look for specific AI bot rules. If you see none, your site is running on defaults that may or may not be what you want.
2. Check your Cloudflare or CDN settings. If you use Cloudflare, Sucuri, or another CDN with bot management, check whether AI bots are being blocked at the network level. This overrides robots.txt.
3. Check your server logs. Look for user-agent strings containing GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, and ChatGPT-User. If you see them, they're accessing your site. If you don't, they're being blocked somewhere, whether by robots.txt, CDN rules, or server configuration.
4. Test your AI visibility. Run 10 category queries across ChatGPT, Perplexity, Claude, and Gemini. Note whether your brand appears. Then check your robots.txt. If you're invisible across all platforms despite having good content, crawler access may be the bottleneck. Tools like RepuAI track your brand's AI presence across platforms continuously, so you can correlate robots.txt changes with citation changes over time. The free AI Visibility Checker gives a quick baseline.
5. Implement, then monitor. After updating your robots.txt, don't expect overnight results. AI effects typically take 2-4 weeks to manifest as crawlers revisit your content. Set a follow-up check for 30 days after changes.
The Bottom Line
Your robots.txt is no longer a set-it-and-forget-it file. In 2026, it's one of the most consequential technical decisions your marketing team makes, because it determines whether your brand exists in the growing number of AI-powered interfaces where buyers research, compare, and shortlist vendors.
The data is clear on the recommended approach for most businesses: allow retrieval crawlers from every major platform, make a deliberate decision about training crawlers based on your content strategy, and audit quarterly as new bots emerge. The brands that get this right will have a structural advantage in AI visibility. The ones running on 2023 defaults are leaving that advantage on the table.
Start with the audit this week. Check your robots.txt, check your CDN, and run 10 queries to see where you stand. The fix might take 15 minutes. The impact compounds for years.