AI-краулеры: GPTBot, ClaudeBot и ваш robots.txt
Umar
GPTBot, ClaudeBot и PerplexityBot ежедневно сканируют ваш сайт, но большинство брендов не знают, каких допускать. Практический гайд 2026 с шаблонами и данными

На вашем сервере есть файл, который тихо решает, смогут ли ChatGPT, Claude, Perplexity и Gemini прочитать ваш сайт. Он называется robots.txt, и у большинства компаний он не обновлялся с 2023 года. Это проблема, потому что ландшафт AI-краулеров в 2026 году выглядит совершенно иначе, чем два года назад.
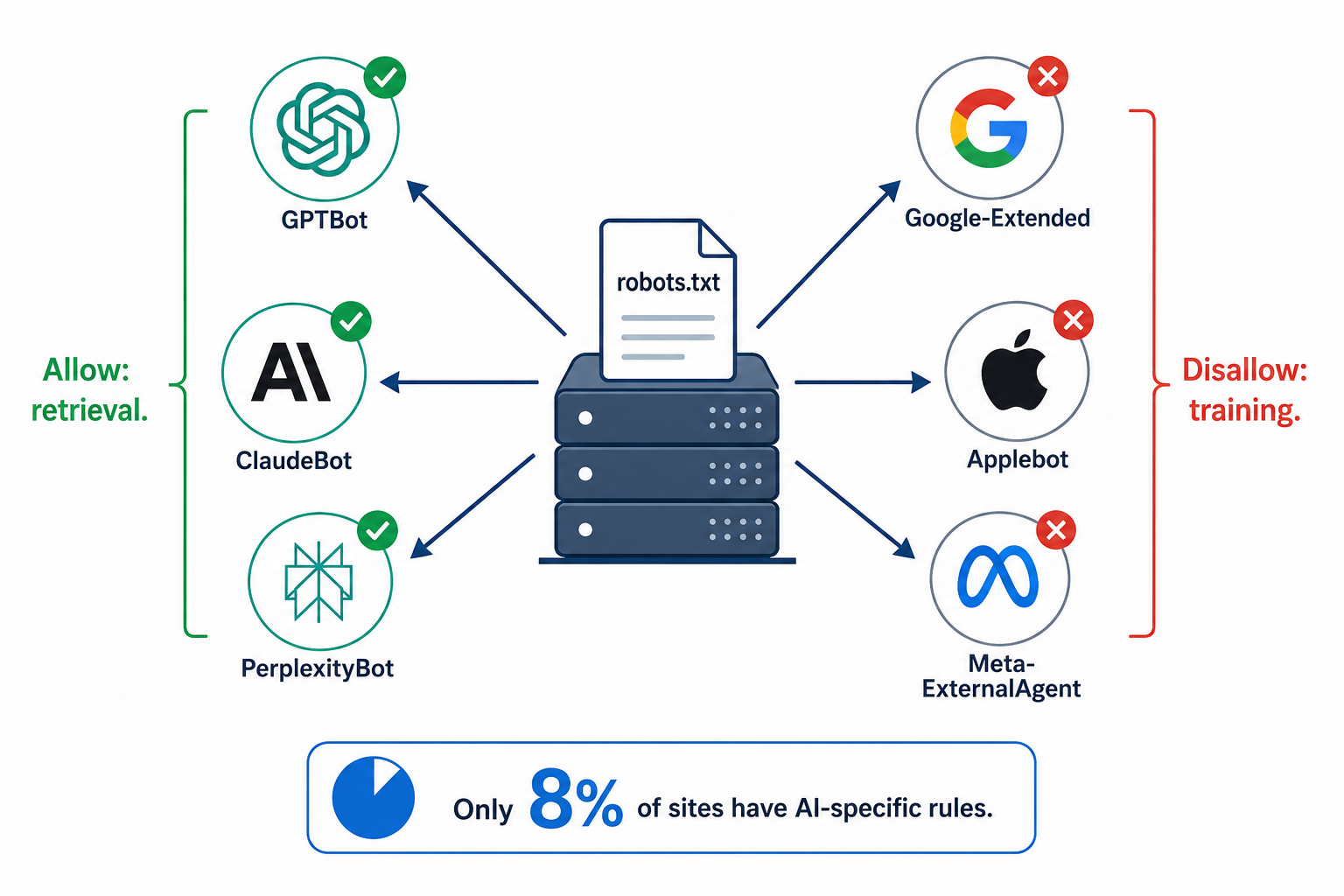
OpenAI теперь использует три отдельных краулера. Anthropic тоже три. Google разделяет обучение ИИ и обычную поисковую индексацию. Applebot вырос на 140% за один месяц и стал шестым крупнейшим AI-ботом в мире. При этом только 8% из топ-10 000 доменов имеют какие-либо AI-специфичные правила в robots.txt. Остальные работают на настройках по умолчанию, которые могут тихо блокировать ИИ-движки от чтения их контента или давать каждой ИИ-компании неограниченный доступ ко всему.
Этот гайд покрывает конкретных ботов, которые важны для видимости бренда, разницу между training- и retrieval-краулерами (различие, о котором большинство маркетологов не знает), и как настроить robots.txt для максимизации AI-цитирования без передачи обучающих данных.
Training-боты vs. Retrieval-боты: различие, которое меняет всё
Самая большая ошибка компаний в работе с AI-краулерами в том, что они воспринимают их как единую категорию. В 2026 году каждый крупный AI-провайдер использует как минимум два типа краулеров, и разница между ними напрямую влияет на видимость вашего бренда.
Training-краулеры собирают контент для создания и улучшения ИИ-моделей. Они сканируют большие объёмы страниц для загрузки в следующее обновление модели. Когда вы блокируете training-краулер, ваш контент перестаёт встраиваться в веса модели при будущем обучении. ИИ постепенно «забывает» актуальную информацию о вашем бренде по мере устаревания его знаний.
Retrieval-краулеры запрашивают конкретные страницы в реальном времени, когда пользователь задаёт ИИ-инструменту вопрос. Они обеспечивают работу функций live search в ChatGPT, Claude и Perplexity. Когда вы блокируете retrieval-краулер, ваши страницы исключаются из результатов AI-поиска немедленно, даже если модель уже имеет определённые знания о вашем бренде из обучающих данных.
Это принципиально важно для принятия решения. Блокировка training-краулеров разумна, если вы хотите защитить проприетарный контент от поглощения весами модели. Блокировка retrieval-краулеров убивает вашу AI-видимость прямо сейчас. Анализ Cloudflare за Q1 2026 показал, что 89,4% всего AI-краулерного трафика служит training- или смешанным целям, и лишь 8% относится к поиску. Retrieval-боты дают мало трафика, но имеют максимальное влияние на ваш бренд.
Практический вывод: вы можете блокировать training и разрешать retrieval. Это самая популярная стратегия в 2026 году, которая защищает ваш контент от обучения моделей и при этом сохраняет видимость бренда в AI-ответах. Но для этого нужно знать, какие боты к какой категории относятся.
Все AI-краулеры, которые важны в 2026 году
Полный список краулеров, для которых вам нужны правила, сгруппированный по провайдерам и назначению.
OpenAI (ChatGPT)
OpenAI использует три краулера, каждый с независимыми правилами robots.txt. Блокировка одного не влияет на остальные.
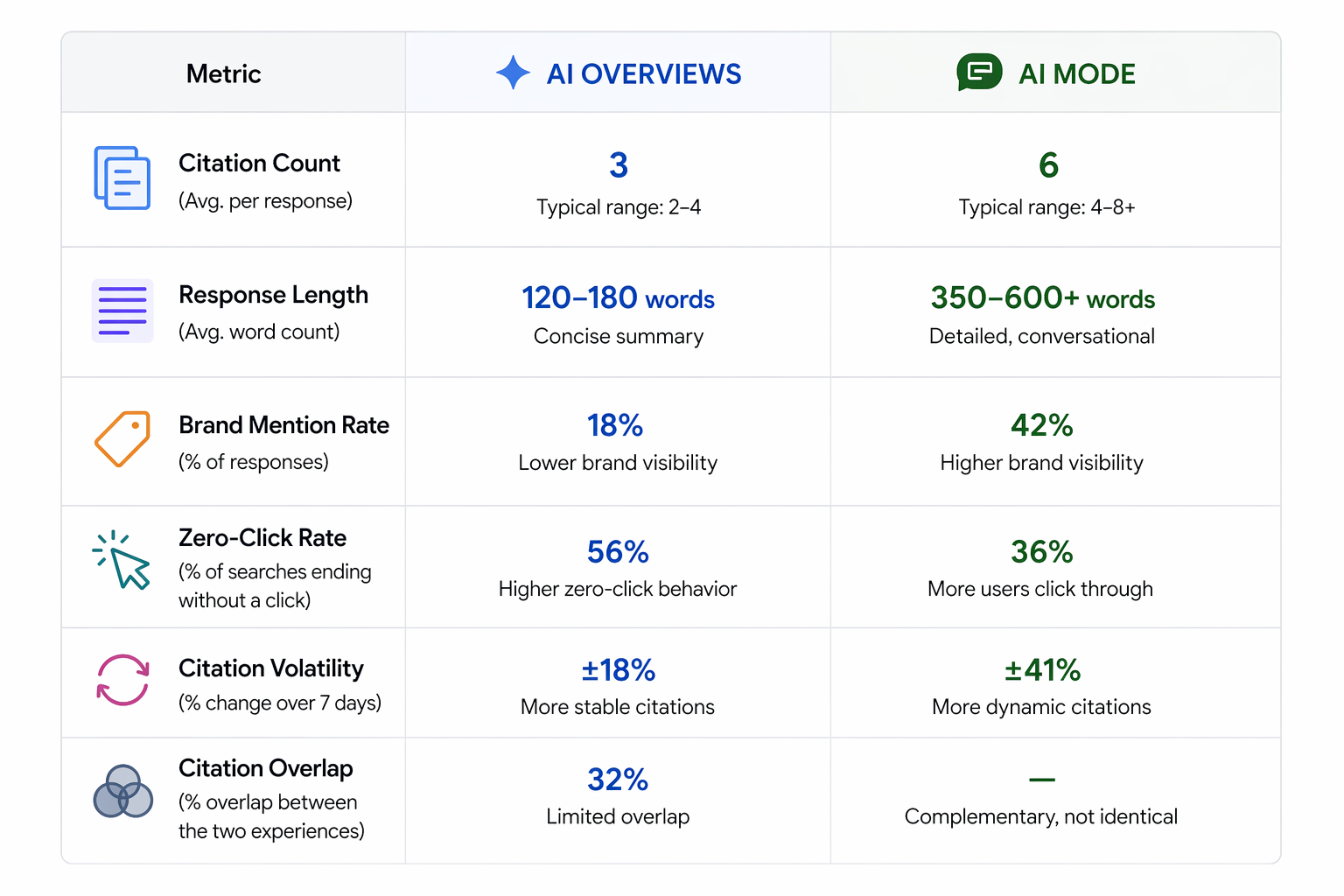
GPTBot это training-краулер. Он собирает контент для улучшения моделей OpenAI. GPTBot самый агрессивный AI-краулер: медиана 4 200 запросов на сайт в день (в 2-4 раза больше любого другого AI-бота по данным 30-дневного исследования серверных логов на 12 production-сайтах). Он повторно посещает популярные страницы каждые 2,4 дня. GPTBot также наиболее блокируемый AI-краулер в мире.
OAI-SearchBot это поисковый индексатор. Он сканирует для построения индекса, который обеспечивает поисковую функцию ChatGPT. Блокировка GPTBot не блокирует OAI-SearchBot. Многие сайты теперь разрешают OAI-SearchBot, блокируя GPTBot, получая попадание в поисковые результаты ChatGPT без вклада в будущее обучение.
ChatGPT-User это retrieval-бот реального времени. Он срабатывает, когда пользователь ChatGPT просит модель просмотреть конкретный URL или выполнить live-поиск. Блокировка этого бота означает, что ChatGPT буквально не может прочитать вашу страницу, когда пользователь спрашивает о вас. PerplexityBot и ChatGPT-User чаще появляются в ALLOW-правилах, чем в DISALLOW, потому что владельцы сайтов понимают, что они приносят реферальный трафик.
Anthropic (Claude)
Anthropic повторяет трёхботовую структуру OpenAI, формально задокументированную в феврале 2026.
ClaudeBot это training-краулер. Он питает корпус предобучения моделей Anthropic. ClaudeBot уступает GPTBot по объёму, примерно 1 800 хитов на сайт в день. Его показатель crawl-to-refer впечатляет: ClaudeBot читает 20 583 страницы на каждый реферал, который он отправляет обратно издателям (для сравнения: у OpenAI соотношение 1 255:1). В апреле 2026 ClaudeBot обогнал CCBot и стал вторым по блокировкам AI-ботом.
Claude-User это пользовательский fetcher, который запускается, когда пользователь Claude просит модель проанализировать конкретную страницу. Блокировка удаляет ваш контент из реальных разговоров Claude.
Claude-SearchBot индексирует контент для улучшения качества поисковых результатов Claude. Он отделён от обучения и от пользовательского fetching.
Google-Extended контролирует, использует ли Google ваш контент для обучения Gemini. Критически важно: блокировка Google-Extended не влияет на ранжирование Google Search и не влияет на AI Overviews. AI Overviews используют стандартный Googlebot. Google-Extended управляет исключительно обучением Gemini.
Прочие
PerplexityBot обеспечивает работу поисковой системы Perplexity. Он тише GPTBot (около 980 хитов в день), но демонстрирует всплески, когда запросы о вашем бренде или категории становятся вирусными. Блокировка полностью удаляет вас из ответов Perplexity.
Meta-ExternalAgent тихо стал краулером #2 с 16,3% трафика, обогнав и ClaudeBot, и GPTBot. Он питает Meta AI в Facebook, Instagram и WhatsApp. Лишь 3,3% доменов упоминают его в robots.txt, что делает его краулером с наибольшим разрывом между долей трафика и активностью блокировки.
Applebot-Extended вырос на 140% за один месяц (с 2,97% до 7,15% AI-трафика) и теперь приближается к доле GPTBot. Если вы игнорировали краулер Apple, вы пропускаете одного из самых быстрорастущих AI-ботов.
Bytespider (ByteDance) имеет задокументированную историю несоблюдения robots.txt. Если вы хотите его заблокировать, понадобятся серверные правила, а не только запись в robots.txt.

Три готовых шаблона robots.txt
Вместо теории приведём три шаблона для наиболее типичных сценариев. Выберите подходящий и адаптируйте.
Шаблон 1: Максимальная AI-видимость
Подходит для: B2B SaaS, агентств, сервисных компаний, всех, кто хочет рекомендаций от ИИ. Разрешает полный доступ каждому крупному AI-краулеру.
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: Applebot-Extended
Allow: /
User-agent: Meta-ExternalAgent
Allow: /
Шаблон 2: Блокировка training, разрешение retrieval
Подходит для: издателей, контент-креаторов, компаний с проприетарными данными, которым нужна AI-видимость в поиске. Это самая популярная стратегия 2026 года.
# Блокировка training-краулеров
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
# Разрешение retrieval/search-краулеров
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Applebot-Extended
Allow: /
Шаблон 3: Селективный доступ по типу контента
Подходит для: компаний со смешанным публичным и проприетарным контентом. Разрешает AI доступ к блогу и маркетинговым страницам, блокируя документацию или закрытые ресурсы.
User-agent: GPTBot
Allow: /blog/
Allow: /about/
Allow: /pricing/
Disallow: /docs/
Disallow: /api/
Disallow: /admin/
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
Disallow: /admin/
Disallow: /api/
Применяйте ту же логику путей к ClaudeBot, Claude-User и PerplexityBot в зависимости от ваших задач.
Ловушка Cloudflare
Если ваш сайт использует Cloudflare (а это более 20% всех сайтов), есть подвох, о котором большинство команд не знает. Переключатель «AI Scrapers and Crawlers» в панели Security Cloudflare блокирует AI-ботов на уровне WAF, до того как robots.txt вообще будет прочитан. Ваш robots.txt может говорить «Allow: /» для каждого AI-краулера, а Cloudflare тихо заблокирует их все.
В одном задокументированном случае PerplexityBot и ClaudeBot отклонялись Cloudflare месяцами, хотя robots.txt сайта был настроен правильно. После отключения AI-блокировки Cloudflare оба краулера появились в серверных логах в течение 48 часов, а AI-реферальный трафик начал поступать в течение шести недель.
Проверьте вашу панель Cloudflare в разделе Security > Bots. Найдите управляемое правило «AI Scrapers and Crawlers». Если оно включено, оно перекрывает всё в вашем robots.txt. Для гранулярного управления по каждому боту используйте функцию AI Crawl Control Cloudflare.
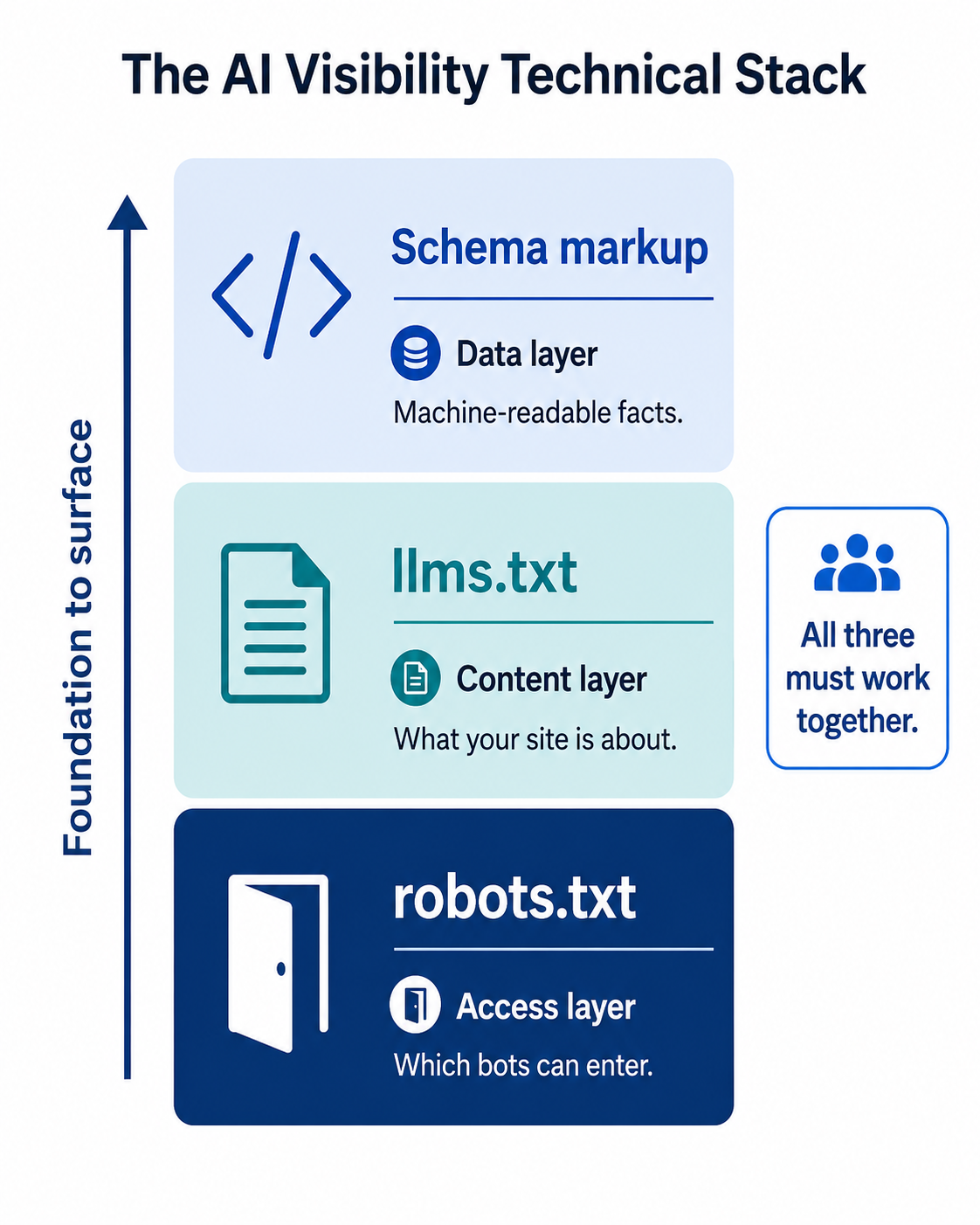
Как robots.txt связан с вашей AI-стратегией
Robots.txt это уровень доступа. Он определяет, могут ли AI-краулеры вообще прочитать ваш контент. Но доступ сам по себе не делает вас видимыми. Он связан с двумя другими техническими компонентами, которые стоит внедрять вместе.
llms.txt это уровень контента. В то время как robots.txt контролирует, какие боты могут войти, llms.txt сообщает ИИ-системам, о чём ваш сайт, в формате, разработанном специально для языковых моделей. Представьте robots.txt как дверь, а llms.txt как приветственный коврик с инструкциями. Если вы внедрили llms.txt, но ваш robots.txt блокирует краулеры, которые его прочитали бы, вы создали коврик, который никто не видит.
Schema-разметка это уровень данных. Structured data даёт ИИ-системам машиночитаемые факты о вашем бренде, продуктах и контенте. Но если краулеры не могут получить доступ к страницам с вашей schema, structured data никогда не будет обработана. 65% страниц, цитируемых AI Mode от Google, включают structured data, а 71% страниц, цитируемых ChatGPT, тоже. Эти страницы должны быть доступны соответствующим краулерам в первую очередь.
Три компонента работают как стек: robots.txt (доступ) > llms.txt (формат) > schema (данные). Правильная настройка одного без остальных оставляет пробелы. Если вы следовали гайдам RepuAI по внедрению schema и попаданию в цитаты ChatGPT, проверка robots.txt это фундамент, который обеспечивает работу этих тактик.
Практический чеклист аудита
Перед внесением изменений проведите аудит текущей настройки:
1. Проверьте robots.txt. Откройте yourdomain.com/robots.txt в браузере. Ищите правила User-agent: * с Disallow: /, которые блокируют всех краулеров, включая AI-ботов. Ищите специфичные AI-правила. Если их нет, ваш сайт работает на настройках по умолчанию, которые могут не соответствовать вашим целям.
2. Проверьте настройки Cloudflare или CDN. Если вы используете Cloudflare, Sucuri или другой CDN с управлением ботами, проверьте, не блокируются ли AI-боты на сетевом уровне. Это перекрывает robots.txt.
3. Проверьте серверные логи. Ищите user-agent строки, содержащие GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot и ChatGPT-User. Если вы их видите, они получают доступ к сайту. Если нет, они блокируются где-то: robots.txt, CDN-правилами или серверной конфигурацией.
4. Протестируйте AI-видимость. Выполните 10 категорийных запросов в ChatGPT, Perplexity, Claude и Gemini. Отметьте, появляется ли ваш бренд. Затем проверьте robots.txt. Если вы невидимы на всех платформах несмотря на хороший контент, доступ краулеров может быть узким местом. RepuAI отслеживает AI-присутствие вашего бренда на платформах непрерывно, позволяя коррелировать изменения robots.txt с изменениями цитирования во времени. Бесплатный AI Visibility Checker даёт быстрый baseline.
5. Внедрите, затем мониторьте. После обновления robots.txt не ждите мгновенных результатов. AI-эффекты обычно проявляются через 2-4 недели по мере повторного сканирования вашего контента краулерами. Запланируйте контрольную проверку через 30 дней после изменений.
Итог
Ваш robots.txt больше не файл из категории «настроил и забыл». В 2026 году это одно из самых значимых технических решений вашей маркетинговой команды, потому что он определяет, существует ли ваш бренд в растущем числе ИИ-интерфейсов, где покупатели исследуют, сравнивают и формируют шорт-листы вендоров.
Данные однозначно рекомендуют подход для большинства бизнесов: разрешайте retrieval-краулеры от каждой крупной платформы, принимайте осознанное решение о training-краулерах на основе вашей контент-стратегии и проводите аудит ежеквартально по мере появления новых ботов. Бренды, которые правильно настроят это, получат структурное преимущество в AI-видимости. Те, кто работает на настройках 2023 года, оставляют это преимущество на столе.
Начните с аудита на этой неделе. Проверьте robots.txt, проверьте CDN и выполните 10 запросов, чтобы увидеть, где вы находитесь. Исправление может занять 15 минут. Его влияние накапливается годами.