Как попасть в цитирования ChatGPT в 2026 году
Umar
ChatGPT цитирует бренды из answer-блоков, оригинальных данных и доверенных сторонних источников. Разбираем, как попасть в ответы ChatGPT в 2026 году
Как попасть в цитирования ChatGPT в 2026 году
Когда пользователь спрашивает ChatGPT про лучший инструмент в вашей категории, модель обычно называет два или три бренда. Если вашего среди них нет, для этого разговора вы просто не существуете. И в отличие от Google, страницы №2 тут не будет.
ChatGPT сейчас обрабатывает больше 2 миллиардов запросов в месяц, и всё большая их часть — это исследование продуктов и оценка поставщиков. Бренды, попадающие в такие ответы, оказались там не случайно. В исследованиях миллионов цитирований всплывают одни и те же структурные паттерны, и удивительно мало из них связано с тем, насколько на самом деле хорош ваш продукт. Ниже — что реально определяет цитирования ChatGPT в 2026 году и как под это подстроиться.
Почему ChatGPT выбирает один бренд и игнорирует другой
ChatGPT читает ваш сайт не так, как человек. Когда пользователь задаёт вопрос, модель использует retrieval-augmented generation (RAG). Она разбивает запрос на более мелкие подзапросы, достаёт страницы, подходящие по семантической близости, оценивает сигналы авторитетности и собирает ответ из того, что нашла.
Отсюда два практических вывода. Во-первых, оптимизации под позиции в ключевиках уже недостаточно: модель не сопоставляет ключевики так, как это делает Google. Она сопоставляет смысл. Во-вторых, цитируемые страницы обычно имеют общие структурные черты, потому что эти черты облегчают модели извлечение информации и доверие к ней.
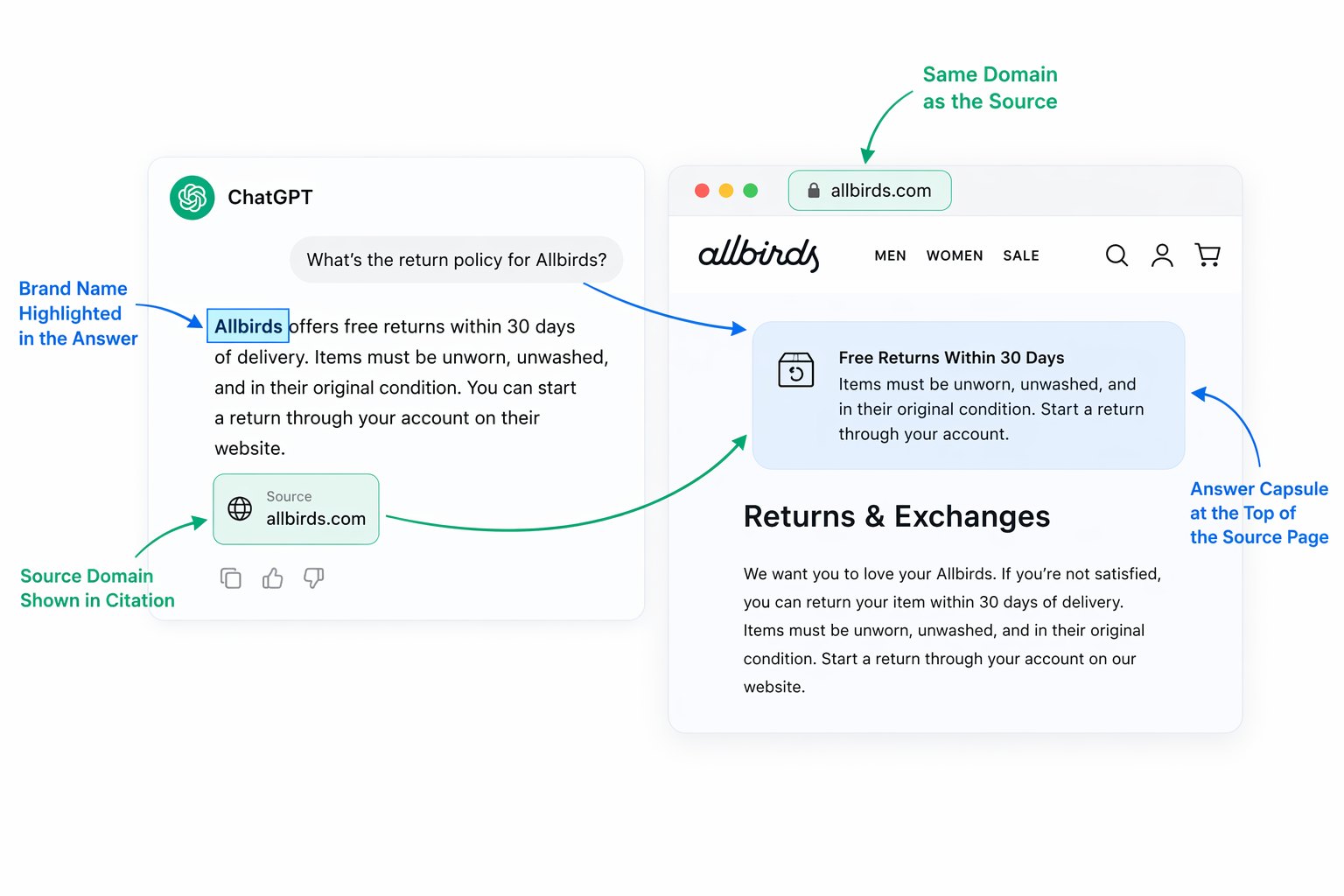
Аудит 15 доменов и почти 7 500 реферальных сессий из ChatGPT, проведённый SearchEngineLand, показал, что у 72,4% цитируемых страниц была одна и та же особенность: короткий самодостаточный блок-ответ в начале страницы. Этого наблюдения уже достаточно, чтобы понять главное. Разобраться, чем AEO, GEO и классический SEO отличаются друг от друга, поможет контекстно встроить всё остальное.
Пять сигналов, которые определяют цитирования ChatGPT
В независимых исследованиях цитирований раз за разом всплывают одни и те же пять сигналов. По отдельности ни один из них не панацея. Собранные вместе три или четыре, они резко повышают вероятность, что модель процитирует именно вас.
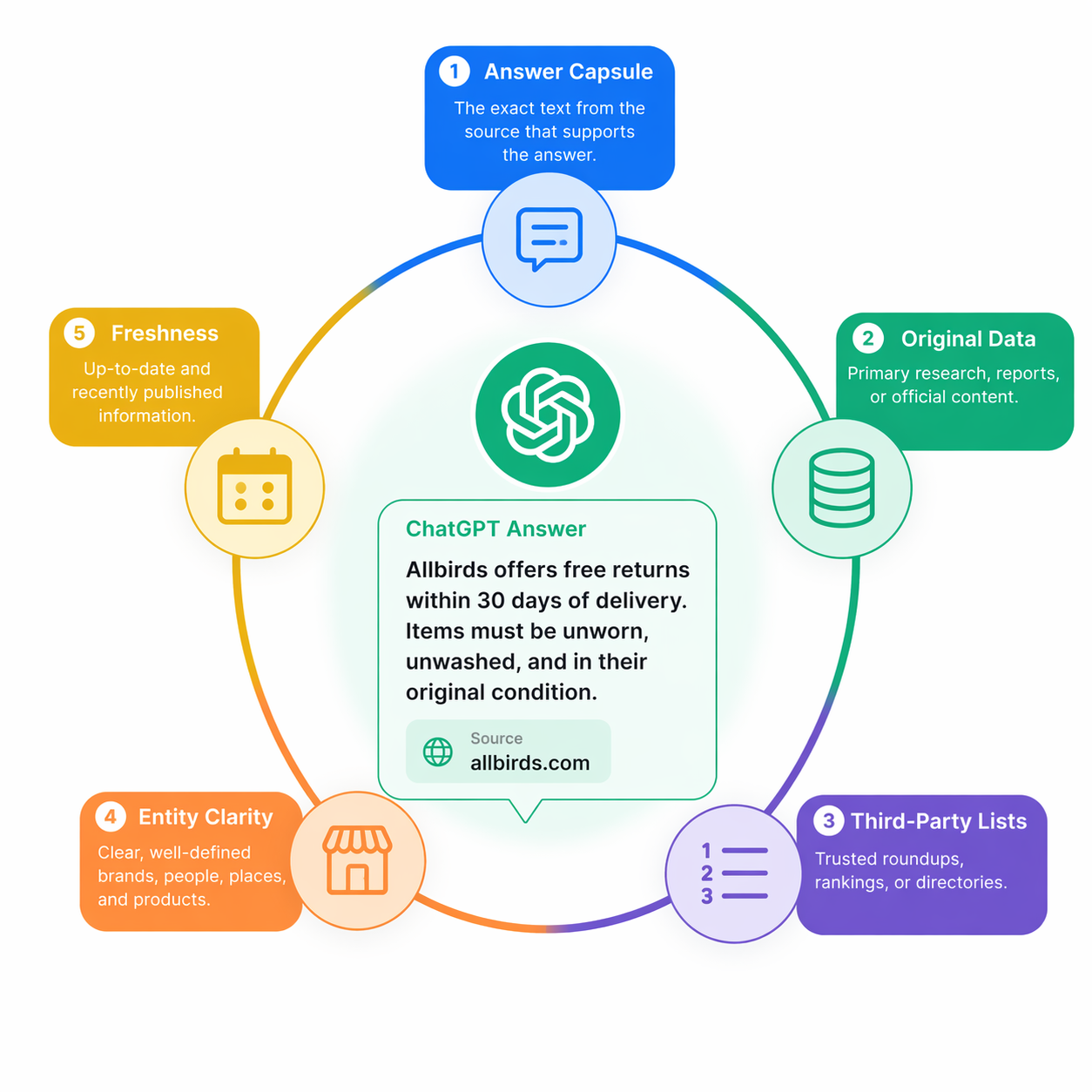
1. Answer capsule в начале страницы
Answer capsule — это абзац на 40–60 слов в начале раздела, который напрямую отвечает на конкретный вопрос. Без оговорок, вступлений и внутренних ссылок внутри блока. Абзац должен читаться самостоятельно, если его вырвать из страницы.
Так устроено потому, что RAG-базы обрабатывают текст определённым образом. Перед извлечением модель режет страницу на векторные «чанки». Чистый и плотный блок-ответ становится почти идеальным чанком. Размытый ответ на четыре абзаца размывает сигнал и, как правило, уступает цитирование конкуренту, написавшему короче и чётче.
2. Оригинальные данные и собственные инсайты
В том же аудите SearchEngineLand 52% цитируемых материалов содержали либо оригинальные данные, либо фирменный инсайт. Когда answer capsule и собственные данные встречались вместе, вероятность цитирования была максимальной. У модели появляется явная причина сослаться именно на вас, а не на десяток однотипных страниц: у вас есть то, чего нет больше ни у кого.
Большой исследовательский бюджет тут не нужен. Опроса 100 клиентов, внутреннего бенчмарка по обезличенным данным продукта или материала в духе «State of [категория] 2026» с реальными цифрами часто достаточно, чтобы стать регулярным источником.
3. Упоминания в сторонних «best of» подборках
Бо́льшая часть цитирований ChatGPT приходит не с вашего домена. Они приходят из сравнительных статей, агрегаторов обзоров и курируемых подборок, которые ранжируются по релевантным коммерческим запросам. Если в вашей категории есть подборка «Топ-10 инструментов X» в топе Google, бренды на позициях 1–5 внутри этой подборки цитируются ChatGPT непропорционально чаще остальных.
Именно поэтому digital PR, гостевые публикации и аутрич авторам подборок тихо перешли из разряда «было бы неплохо» в один из самых окупаемых рычагов в работе с AI-видимостью.
4. Чёткость сущности (entity clarity)
ChatGPT мыслит не URL-ами, а сущностями. Когда кто-то спрашивает про инструменты управления проектами, модель вытаскивает информацию про Asana, Monday.com, ClickUp и цитирует страницы, связанные с этими сущностями. Если ваш бренд не распознан моделью как сущность, вы невидимы, как бы хорош ни был контент.
Чёткость сущности складывается из трёх вещей: полноценной Organization schema на главной (с sameAs-ссылками на Wikipedia, Wikidata, Crunchbase и LinkedIn), понятной страницы About с последовательным написанием бренда по всему вебу и сторонних упоминаний, подкрепляющих, что вы делаете и для кого. В нашем гайде по schema markup для AI-видимости разобрана конкретная разметка, которую стоит внедрить.
5. Свежесть
У AI-систем сильный уклон в пользу свежего контента. Данные нескольких платформ мониторинга показывают, что частота цитирований резко падает, когда страница перестаёт обновляться примерно на 90 дней. Гайд двухлетней давности без обновлений будет проигрывать новой статье по той же теме, даже если старая объективно более полная.
Переписывать страницы с нуля не нужно. Обычно достаточно добавить свежую цифру, обновить скриншот, подменить пример и сдвинуть дату «Последнее обновление». Этим вы обнуляете таймер.
Технический фундамент, который нельзя пропустить
Прежде чем браться за контент, убедитесь, что ChatGPT вообще может читать ваши страницы. Именно на этом большинство брендов спотыкается ещё до старта.
Проверьте robots.txt
ChatGPT обходит контент через два основных user-agent: GPTBot (для тренировочных данных) и ChatGPT-User (для живого браузинга). Perplexity использует PerplexityBot, Claude — ClaudeBot, Google — Google-Extended для AI-специфичного обхода. Если любой из них в disallow, соответствующая платформа вас не процитирует.
В 2024 году Cloudflare поменял дефолтную конфигурацию и начал автоматически блокировать AI-ботов. Если вы на Cloudflare и не включали AI-краулеров обратно вручную, есть реальный шанс, что прямо сейчас ваш сайт невидим для ChatGPT. Перед чем бы то ни было проверьте дашборд AI Crawl Metrics в Cloudflare и логи сервера на активность GPTBot.
Отдавайте важный контент на сервере
AI-краулеры не исполняют JavaScript так, как это делает браузер. Они читают сырой HTML, который вернул сервер. Если цены, ключевые функции или основной контент спрятаны за табом, дропдауном или клиентским рендером, краулер их не увидит.
Один специалист рассказывал, как наиболее цитируемая страница с ценами у его клиента полностью потеряла цитирования после миграции, спрятавшей цены в сворачиваемый компонент. Исправило ситуацию возвращение цен в статический HTML. Цитирования восстановились примерно за шесть недель.
Внешний слой: упоминания за пределами сайта
Во всех крупных исследованиях цитирований виден один и тот же паттерн: большинство упоминаний в ChatGPT приходит не с брендового контента. Они приходят с площадок, которые бренд не контролирует целиком.
Reddit — самый цитируемый домен в AI-поиске: по данным Superlines, он появляется примерно в 34,7% отслеженных ответов ChatGPT. Доля цитирований с YouTube росла быстро, поднявшись с 19% до 39% за пятимесячный период начала 2026-го. Площадки с отзывами (G2, Capterra, Trustpilot) имеют серьёзный вес в запросах на оценку поставщиков, а средний рейтинг ниже 4,0 заметно снижает вероятность цитирования в конкурентных категориях.
Практический вывод: бренды, присутствующие на трёх и более доверенных внешних площадках, цитируются заметно чаще, чем те, кто полагается только на свой сайт. Относитесь к Reddit, YouTube и ресурсам с отзывами как к площади для цитирований, а не как к второстепенным каналам.
Чек-лист из 7 шагов, чтобы начать попадать в ответы
Проходите по порядку. Первые три шага дают максимальный рычаг большинству команд.
- Проверьте доступ краулеров. Убедитесь, что robots.txt разрешает GPTBot, ChatGPT-User, ClaudeBot, PerplexityBot и Google-Extended. Если вы на Cloudflare, отдельно проверьте настройки AI-ботов.
- Добавьте answer capsule на топ-10 страниц. Абзац на 40–60 слов в начале, прямо отвечающий на запрос, под который заточена страница. Без ссылок внутри блока.
- Публикуйте один материал с оригинальными данными раз в квартал. Небольшой опрос клиентов, бенчмарк на данных вашего продукта или метрика, которой нет больше ни у кого.
- Прокачайте entity-след. Полноценная Organization schema с sameAs-ссылками, последовательное написание бренда везде и, в идеале, запись в Wikipedia или Wikidata.
- Заберите 2–3 места в «best of» подборках в этом квартале. Целитесь в посты, которые уже в топ-10 Google по запросам вашей категории.
- Соберите присутствие с рейтингом 4,0+ на той площадке отзывов, которую реально использует ваша категория. Просите клиентов описывать конкретные кейсы, а не просто ставить звёзды.
- Обновляйте топовые цитируемые страницы каждые 90 дней. Обновите статистику, добавьте новый пример, смените видимую дату «Последнее обновление». Можно также сгенерировать стартовый llms.txt-файл, чтобы описать ключевой контент для AI-краулеров.

Как понять, что работа даёт результат
Всё это бессмысленно, если нет способа измерить эффект. Google Analytics большую часть рефералов ChatGPT показывает как direct или обезличенный трафик, а Search Console про AI-движки вообще не знает. Нужно видеть две вещи по отдельности: появляется ли ваш бренд в AI-ответах по тем промптам, которые реально используют покупатели, и с каких страниц и источников эти ответы собираются.
Именно этот пробел закрывает RepuAI. Сервис отслеживает, как ваш бренд появляется в ChatGPT, Perplexity, Gemini и Claude по нужным вам промптам, отслеживает тональность и источники цитирований во времени и сигнализирует, когда конкурент занимает ваше место в ключевом ответе. Перед тем как что-то менять, можно также прогнать бесплатную проверку AI-видимости и посмотреть, как ваш сайт выглядит для LLM-краулеров сегодня и каких сигналов не хватает. В связке с понятной системой KPI для AI-видимости за 60 дней станет ясно, идёт ли работа в плюс.
Накопительный эффект
Цитирования ChatGPT складываются в накопительный эффект. Как только модель признаёт ваш бренд авторитетным в категории, та же сущность начинает всплывать в десятках смежных промптов. Чтобы туда добраться, обычно нужно 90–180 дней системной работы с контентом, техническим доступом и внешним присутствием.
Начните с капсулы. Почините краулер. Заберите одно место в подборке. Через месяц повторите. Бренды, которых цитируют сегодня, — это те, кто полгода назад начал относиться к AI-видимости как к дисциплине, а не как к разовому аудиту.



