AI Crawlers explicados: GPTBot, ClaudeBot y tu robots.txt
Umar
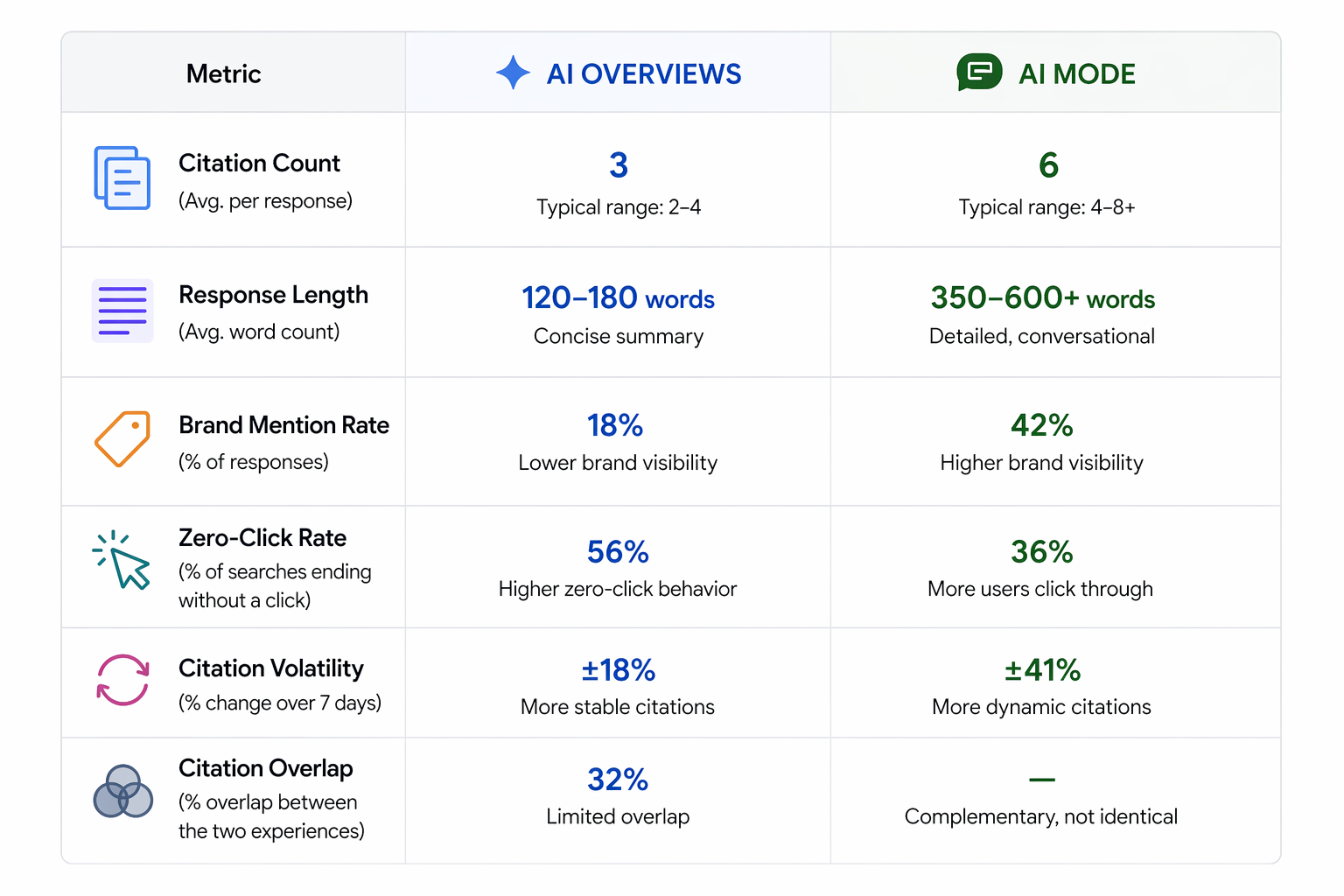
GPTBot, ClaudeBot y PerplexityBot visitan tu sitio cada día, pero la mayoría de marcas no sabe cuáles permitir. Guía práctica 2026 con plantillas y datos de visibilidad

Hay un archivo en tu servidor que decide silenciosamente si ChatGPT, Claude, Perplexity y Gemini pueden leer tu sitio web. Se llama robots.txt, y en la mayoría de las empresas no se ha actualizado desde 2023. Eso es un problema, porque el panorama de los AI crawlers en 2026 no se parece en nada al de hace dos años.
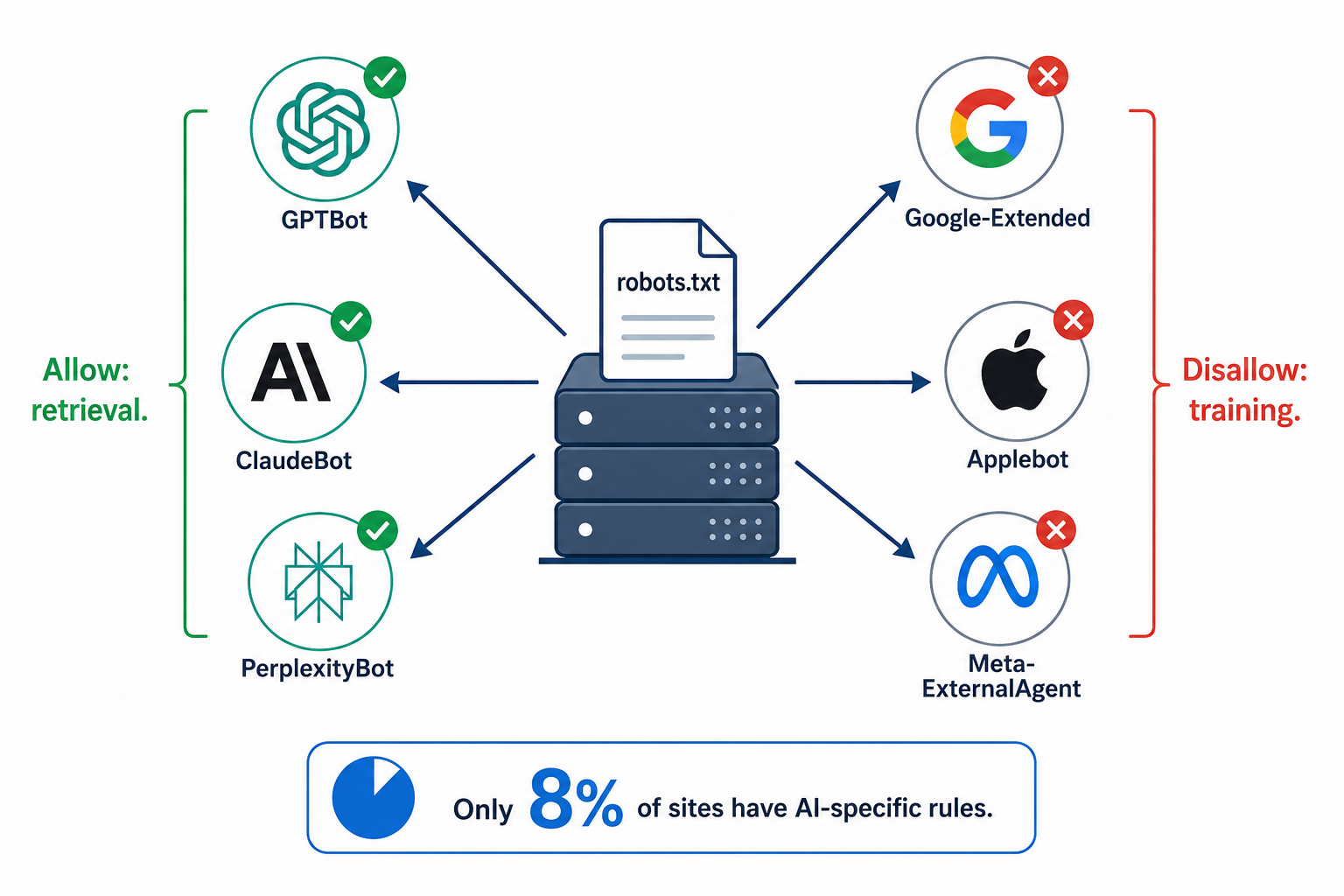
OpenAI ahora ejecuta tres crawlers separados. Anthropic también tres. Google separa el entrenamiento de IA de la indexación de búsqueda normal. Applebot creció un 140% en un solo mes y ahora es el sexto bot de IA más grande del mundo. Mientras tanto, solo el 8% de los 10.000 dominios principales tienen alguna regla específica para IA en su robots.txt. El resto funciona con configuraciones por defecto que podrían estar bloqueando silenciosamente a los motores de IA de leer su contenido, o dando a cada empresa de IA acceso sin restricciones a todo.
Esta guía cubre los bots específicos que importan para la visibilidad de marca, la diferencia entre crawlers de training y de retrieval (una distinción que la mayoría de los profesionales de marketing desconoce), y cómo configurar tu robots.txt para maximizar las citas de IA sin ceder datos de entrenamiento.
Training bots vs. retrieval bots: la distinción que lo cambia todo
El mayor error que cometen las empresas con los AI crawlers es tratarlos como una sola categoría. En 2026, cada proveedor importante de IA opera al menos dos tipos de crawlers, y la diferencia entre ellos tiene implicaciones directas para la visibilidad de tu marca.
Los crawlers de training recopilan contenido para construir y mejorar modelos de IA. Rastrean grandes volúmenes de páginas para alimentar la próxima actualización del modelo. Cuando bloqueas un crawler de training, tu contenido deja de codificarse en los pesos del modelo durante futuros entrenamientos. La IA gradualmente "olvida" la información actual de tu marca a medida que sus conocimientos se vuelven obsoletos.
Los crawlers de retrieval obtienen páginas específicas en tiempo real cuando un usuario hace una pregunta a una herramienta de IA. Son los que alimentan las funciones de búsqueda en vivo de ChatGPT, Claude y Perplexity. Cuando bloqueas un crawler de retrieval, tus páginas quedan excluidas de los resultados de búsqueda de IA inmediatamente, incluso si el modelo ya tiene algún conocimiento de tu marca de sus datos de entrenamiento.
Esto importa enormemente para la decisión que tomes. Bloquear los crawlers de training es una opción razonable si quieres proteger contenido propietario de ser absorbido por los pesos del modelo. Bloquear los crawlers de retrieval elimina tu visibilidad en búsqueda de IA ahora mismo. Un análisis de Cloudflare del Q1 2026 encontró que el 89,4% de todo el tráfico de AI crawlers sirve propósitos de training o mixtos, mientras que solo el 8% está relacionado con búsqueda. Los bots de retrieval generan poco tráfico pero tienen el máximo impacto en tu marca.
La conclusión práctica: puedes bloquear training y permitir retrieval. Esta es la estrategia más popular en 2026, y protege tu contenido del entrenamiento de modelos mientras mantiene tu marca visible en las respuestas de búsqueda de IA. Pero necesitas saber qué bots pertenecen a cada categoría.
Todos los AI crawlers que importan en 2026
La lista completa de crawlers para los que necesitas reglas, organizada por proveedor y propósito.
OpenAI (ChatGPT)
OpenAI ejecuta tres crawlers, cada uno con reglas independientes de robots.txt. Bloquear uno no afecta a los demás.
GPTBot es el crawler de training. Recopila contenido para mejorar los modelos de OpenAI. GPTBot es el AI crawler más agresivo: una mediana de 4.200 peticiones por sitio al día (2-4 veces más que cualquier otro bot de IA, según un estudio de 30 días de logs de servidor en 12 sitios en producción). Revisita las páginas de alto tráfico cada 2,4 días. GPTBot es también el AI crawler más bloqueado del mundo.
OAI-SearchBot es el indexador de búsqueda. Rastrea para construir el índice que alimenta la función de búsqueda de ChatGPT. Bloquear GPTBot no bloquea OAI-SearchBot. Muchos sitios ahora permiten OAI-SearchBot mientras bloquean GPTBot, consiguiendo que su contenido aparezca en los resultados de búsqueda de ChatGPT sin contribuir al futuro entrenamiento.
ChatGPT-User es el bot de retrieval en tiempo real. Se activa cuando un usuario de ChatGPT pide al modelo que navegue una URL específica o realice una búsqueda web en vivo. Bloquear este bot significa que ChatGPT literalmente no puede leer tu página cuando un usuario pregunta sobre ti. PerplexityBot y ChatGPT-User aparecen más en reglas ALLOW que en DISALLOW en el dataset de Cloudflare, porque los propietarios de sitios reconocen que generan tráfico de referencia.
Anthropic (Claude)
Anthropic replica la estructura de tres bots de OpenAI, formalmente documentada en febrero de 2026.
ClaudeBot es el crawler de training. Alimenta el corpus de preentrenamiento de los modelos de Anthropic. ClaudeBot está por detrás de GPTBot en volumen, con aproximadamente 1.800 hits por sitio al día. Su ratio de crawl-to-refer es llamativo: ClaudeBot lee 20.583 páginas por cada referencia que envía de vuelta a los editores (comparado con el ratio de 1.255:1 de OpenAI). En abril de 2026, ClaudeBot superó a CCBot y se convirtió en el segundo bot de IA más bloqueado por recuento total.
Claude-User es el fetcher iniciado por el usuario que se ejecuta cuando un usuario de Claude pide al modelo que analice una página específica. Bloquearlo elimina tu contenido de las conversaciones de Claude en tiempo real.
Claude-SearchBot indexa contenido para mejorar la calidad de los resultados de búsqueda de Claude. Es independiente del entrenamiento y del fetching iniciado por usuario.
Google-Extended controla si Google usa tu contenido para entrenar Gemini. Es crítico entender que bloquear Google-Extended no afecta el ranking de Google Search ni los AI Overviews. Los AI Overviews usan el Googlebot estándar. Google-Extended controla exclusivamente el entrenamiento de Gemini.
Otros
PerplexityBot alimenta el motor de búsqueda de Perplexity. Es más silencioso que GPTBot (unas 980 peticiones al día) pero muestra picos cuando las consultas sobre tu marca o categoría se viralizan. Bloquearlo te elimina de las respuestas de Perplexity por completo.
Meta-ExternalAgent se convirtió silenciosamente en el crawler #2 con el 16,3% del tráfico, superando tanto a ClaudeBot como a GPTBot. Alimenta Meta AI en Facebook, Instagram y WhatsApp. Solo el 3,3% de los dominios lo referencian en robots.txt, lo que lo convierte en el crawler con la mayor brecha entre cuota de tráfico y actividad de bloqueo.
Applebot-Extended creció un 140% en un solo mes (del 2,97% al 7,15% del tráfico de IA) y ahora se acerca a la cuota de GPTBot. Si has estado ignorando el crawler de Apple, te estás perdiendo uno de los bots de IA de mayor crecimiento.
Bytespider (ByteDance) tiene un historial documentado de no respetar robots.txt. Si quieres bloquearlo, necesitarás reglas a nivel de servidor, no solo una entrada en robots.txt.

Tres plantillas de robots.txt listas para usar
En lugar de explicar teoría, aquí tienes tres plantillas para los escenarios más comunes. Elige la que encaje con tu situación y adáptala.
Plantilla 1: Máxima visibilidad en IA
Ideal para: B2B SaaS, agencias, empresas de servicios, cualquiera que quiera ser recomendado por la IA. Permite acceso completo a cada crawler de IA importante.
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: Applebot-Extended
Allow: /
User-agent: Meta-ExternalAgent
Allow: /
Plantilla 2: Bloquear training, permitir retrieval
Ideal para: editores, creadores de contenido, empresas con datos propietarios que aún quieren visibilidad en búsqueda de IA. Esta es la estrategia más popular en 2026.
# Bloquear crawlers de training
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
# Permitir crawlers de retrieval/búsqueda
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Applebot-Extended
Allow: /
Plantilla 3: Acceso selectivo por tipo de contenido
Ideal para: empresas con contenido mixto público y propietario. Permite acceso de IA a tu blog y páginas de marketing mientras bloquea documentación o recursos cerrados.
User-agent: GPTBot
Allow: /blog/
Allow: /about/
Allow: /pricing/
Disallow: /docs/
Disallow: /api/
Disallow: /admin/
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
Disallow: /admin/
Disallow: /api/
Aplica la misma lógica de rutas a ClaudeBot, Claude-User y PerplexityBot según tus necesidades.
La trampa de Cloudflare
Si tu sitio usa Cloudflare (y más del 20% de todos los sitios lo hace), hay una trampa que la mayoría de los equipos desconoce. El interruptor "AI Scrapers and Crawlers" en el panel de Security de Cloudflare bloquea los bots de IA a nivel de WAF, antes de que robots.txt siquiera sea consultado. Tu robots.txt puede decir "Allow: /" para cada AI crawler, y Cloudflare los bloquea silenciosamente a todos.
En un caso documentado, PerplexityBot y ClaudeBot estaban siendo rechazados por Cloudflare durante meses mientras el robots.txt del sitio estaba correctamente configurado. Tras desactivar el bloqueo de IA de Cloudflare, ambos crawlers aparecieron en los logs del servidor en 48 horas, y el tráfico de referencia de IA comenzó a llegar en seis semanas.
Revisa tu panel de Cloudflare en Security > Bots. Busca la regla gestionada "AI Scrapers and Crawlers". Si está activada, anula todo lo que haya en tu robots.txt. Para control granular por bot, usa la función AI Crawl Control de Cloudflare.
Cómo robots.txt se conecta con tu estrategia de IA más amplia
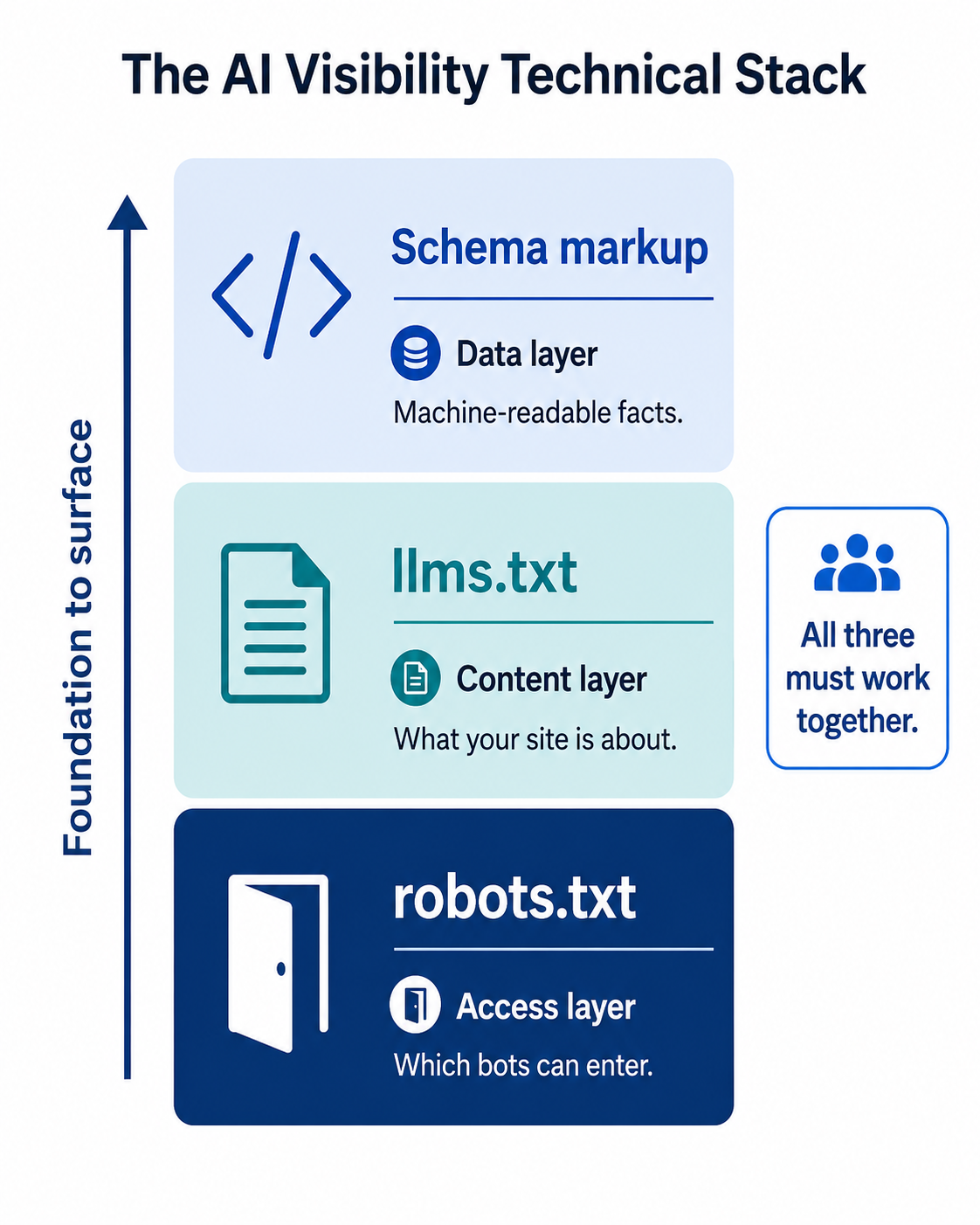
Robots.txt es la capa de acceso. Determina si los AI crawlers pueden siquiera leer tu contenido. Pero el acceso por sí solo no te hace visible. Se conecta con otros dos componentes técnicos que deberías implementar juntos.
llms.txt es la capa de contenido. Mientras robots.txt controla qué bots pueden entrar, llms.txt dice a los sistemas de IA de qué trata tu sitio en un formato diseñado específicamente para modelos de lenguaje. Piensa en robots.txt como la puerta y llms.txt como el felpudo de bienvenida con instrucciones. Si has implementado llms.txt pero tu robots.txt bloquea los crawlers que lo leerían, has construido un felpudo que nadie puede ver.
Schema markup es la capa de datos. Los datos estructurados dan a los sistemas de IA hechos legibles por máquinas sobre tu marca, productos y contenido. Pero si los crawlers no pueden acceder a las páginas con tu schema, los datos estructurados nunca se procesan. El 65% de las páginas citadas por el AI Mode de Google incluyen datos estructurados, y el 71% de las citadas por ChatGPT también. Esas páginas necesitan ser accesibles para los crawlers relevantes primero.
Los tres funcionan como una pila: robots.txt (acceso) > llms.txt (formato) > schema (datos). Acertar con uno sin los otros deja huecos. Si has seguido las guías de RepuAI sobre implementación de schema y cómo ser citado por ChatGPT, comprobar tu robots.txt es el cimiento que hace funcionar esas tácticas.
Checklist práctico de auditoría
Antes de hacer cambios, audita tu configuración actual:
1. Comprueba tu robots.txt. Visita tudominio.com/robots.txt en un navegador. Busca cualquier regla User-agent: * con Disallow: /, que bloquea todos los crawlers incluidos los bots de IA. Busca reglas específicas de IA. Si no hay ninguna, tu sitio funciona con configuraciones por defecto que pueden no coincidir con tus objetivos.
2. Comprueba la configuración de Cloudflare o tu CDN. Si usas Cloudflare, Sucuri u otro CDN con gestión de bots, comprueba si los bots de IA están siendo bloqueados a nivel de red. Esto anula robots.txt.
3. Comprueba los logs del servidor. Busca cadenas de user-agent que contengan GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot y ChatGPT-User. Si los ves, están accediendo a tu sitio. Si no, están siendo bloqueados en algún punto: robots.txt, reglas del CDN o configuración del servidor.
4. Testea tu visibilidad en IA. Ejecuta 10 consultas de categoría en ChatGPT, Perplexity, Claude y Gemini. Anota si tu marca aparece. Luego comprueba tu robots.txt. Si eres invisible en todas las plataformas a pesar de tener buen contenido, el acceso de crawlers puede ser el cuello de botella. RepuAI rastrea la presencia de tu marca en IA a través de las plataformas continuamente, para que puedas correlacionar cambios en robots.txt con cambios en citaciones a lo largo del tiempo. El AI Visibility Checker gratuito da una línea base rápida.
5. Implementa y luego monitoriza. Tras actualizar tu robots.txt, no esperes resultados de la noche a la mañana. Los efectos en IA suelen manifestarse en 2-4 semanas a medida que los crawlers vuelven a visitar tu contenido. Programa una comprobación de seguimiento a los 30 días de los cambios.
La conclusión
Tu robots.txt ya no es un archivo de tipo "configura y olvida." En 2026, es una de las decisiones técnicas más importantes que toma tu equipo de marketing, porque determina si tu marca existe en el número creciente de interfaces impulsadas por IA donde los compradores investigan, comparan y elaboran listas cortas de proveedores.
Los datos son claros sobre el enfoque recomendado para la mayoría de negocios: permite los crawlers de retrieval de cada plataforma importante, toma una decisión deliberada sobre los crawlers de training basándote en tu estrategia de contenido, y audita trimestralmente a medida que aparecen nuevos bots. Las marcas que acierten con esto tendrán una ventaja estructural en visibilidad de IA. Las que funcionen con configuraciones de 2023 están dejando esa ventaja sobre la mesa.
Empieza con la auditoría esta semana. Comprueba tu robots.txt, comprueba tu CDN y ejecuta 10 consultas para ver dónde estás. La corrección puede llevar 15 minutos. Su impacto se acumula durante años.